模块 API(Module API)
一、概述
模块(module):是按业务领域划分和管理的最小单元,是一组功能、界面的集合。模块化是将程序拆解为多个独立模块,每个模块负责实现一项子功能,最终组合成完整系统,以达成整体功能需求。通常依据业务领域划分模块,将同一业务范畴内的数据定义、规则逻辑和可执行代码归集到同一模块中 。
二、模块 Module
(一)模块的定义
Oinone 的模块定义文件通过 Java 类来声明模块,并指定相应的模块元数据。在 Oinone 中,所有模块均继承自PamirsModule。以expenses模块为例:
package pro.shushi.oinone.trutorials.expenses.api;
import org.springframework.stereotype.Component;
import pro.shushi.pamirs.meta.annotation.Module;
import pro.shushi.pamirs.meta.base.PamirsModule;
import pro.shushi.pamirs.meta.common.constants.ModuleConstants;
@Component
@Module(
name = ExpensesModule.MODULE_NAME,
displayName = "费用管理",
version = "1.0.0",
priority = 1,
dependencies = {ModuleConstants.MODULE_BASE}
)
@Module.module(ExpensesModule.MODULE_MODULE)
@Module.Advanced(selfBuilt = true, application = true)
public class ExpensesModule implements PamirsModule {
public static final String MODULE_MODULE = "expenses";
public static final String MODULE_NAME = "expenses";
@Override
public String[] packagePrefix() {
return new String[]{
"pro.shushi.oinone.trutorials.expenses"
};
}
}- 导入必要的类:引入了 Spring 的
@Component注解以及自定义模块相关的注解和接口。 - 类定义:
ExpensesModule类实现了PamirsModule接口。 - 配置注解
通过@Module的name属性配置模块技术名称,前端与后端交互协议使用模块技术名称来定位模块。
通过@Module的displayName属性配置模块展示名称,在产品视觉交互层展现。
通过@Module的version属性配置模块版本,系统会比较版本号来决定模块是否需要进行升级。
通过@Module的priority属性配置模块优先级(数字越小,优先级越高),系统会根据优先级取优先级最高的应用设置的首页来作为整个平台的首页。
通过@Module的dependencies属性和exclusions属性来配置模块间的依赖互斥关系,值为模块编码数组。如果模块继承了另一模块的模型或者与另一模块的模型建立了关联关系,则需要为该模块的依赖模块列表配置另一模块的模块编码。
通过@Module.module配置模块编码,模块编码是模块在系统中的唯一标识。
通过@Module.Advanced的selfBuilt属性配置模块是否为平台自建模块。
通过@Module.Advanced的application属性配置模块是否为应用(具有视觉交互页面的模块)。模块切换组件只能查看到应用。
- 常量定义:定义了
MODULE_MODULE和MODULE_NAME常量,分别表示模块的标识和名称。
| 属性 | 默认取值规则 | 命名规范 |
|---|---|---|
| module | 无默认值 开发人员定义规范示例: {项目名称}_ | 1. 使用下划线命名法 2. 仅支持数字、大写或小写字母、下划线 3. 必须以字母开头 4. 不能以下划线结尾 5. 长度必须大于等4且小于等于128个字符 |
| name | 无默认值 | 1. 使用大驼峰命名法 2. 仅支持数字、字母 3. 必须以字母开头 4. 长度必须小于等于128个字符 |
- 方法实现:
packagePrefix()方法返回该模块所包含的package前缀数组。
注意
Oinone 实例总会安装 base 模块,但仍需将其指定为依赖项,以确保 base 更新时,你的模块也会更新。
注意
@Module.Advanced的application属性配置模块是否为应用(具有视觉交互页面的模块)。非应用模块没有交互入口。
警告
模块包路径由packagePrefix方法返回,如果不同Oinone模块包含相同的包路径,会导致元数据加载出问题。
警告
模块一经安装直到卸载,不可变编码不可变更,否则系统会将其识别为新的元数据。
(二)注解配置
1、@Module
@Module
├── displayName 显示名称
├── name 技术名称
├── version 安装版本
├── category 分类编码
├── summary 描述摘要
├── dependencies 依赖模块编码列表
├── exclusions 互斥模块编码列表
├── priority 排序
├── module 模块编码
│ └── value
├── Ds 逻辑数据源名
│ └── value
├── Hook 排除拦截器列表
│ └── excludes
├── Advanced 更多配置
│ ├── website 站点
│ ├── author 作者
│ ├── description 描述
│ ├── application 是否为应用
│ ├── demo 是否演示应用
│ ├── web 是否web应用
│ ├── toBuy 是否需要跳转到website去购买
│ ├── selfBuilt 是否自建应用
│ ├── license 许可证,枚举默认:PEEL1
│ ├── maintainer 维护者
│ ├── contributors 贡献者
│ └── url 代码库地址
├── Fuse 低无一体融合模块
2、@UxHomepage
@UxHomepage 模块主页
└── UxRoute
3、@UxAppLogo
@UxAppLogo
└── logo 图标
(三)模块元信息
1、ModuleDefinition
| 元素数据构成 | 含义 | 对应注解 | 备注 |
|---|---|---|---|
| displayName | 显示名称 | @Module( displayName="", name="", version="", category="", summary="", dependencies={"",""}, exclusions={"",""}, priority=1L ) | |
| name | 技术名称 | ||
| latestVersion | 安装版本 | ||
| category | 分类编码 | ||
| summary | 描述摘要 | ||
| moduleDependencies | 依赖模块编码列表 | ||
| moduleExclusions | 互斥模块编码列表 | ||
| priority | 排序 | ||
| module | 模块编码 | @Module.module("") | |
| dsKey | 逻辑数据源名 | @Module.Ds("") | |
| excludeHooks | 排除拦截器列表 | @Module.Hook(excludes={"",""}) | |
| website | 站点 | @Module.Advanced( website="http://www.oinone.top", author="oinone", description="oinone", application=false, demo=false, web=false, toBuy=false, selfBuilt=true, license=SoftwareLicenseEnum.PEEL1, maintainer="oinone", contributors="oinone", url="http://git.com" ) | |
| author | module的作者 | ||
| description | 描述 | ||
| application | 是否应用 | ||
| demo | 是否演示应用 | ||
| web | 是否web应用 | ||
| toBuy | 是否需要跳转到website去购买 | ||
| selfBuilt | 自建应用 | ||
| license | 许可证 | 默认PEEL1 可选范围: GPL2 GPL2ORLATER GPL3 GPL3ORLATER AGPL3 LGPL3 ORTHEROSI PEEL1 PPL1 ORTHERPROPRIETARY | |
| maintainer | 维护者 | ||
| contributors | 贡献者列表 | ||
| url | 代码库的地址 | ||
| boot | 是否自动安装的引导启动项 | @Boot | 加上该注解代表: 启动时会自动安装,不管yml文件的modules是否配置 |
| moduleClazz | 模块定义所在类 | 只有用代码编写的模块才有 | |
| packagePrefix | 包路径,用于扫描该模块下的其他元数据 | ||
| dependentPackagePrefix | 依赖模块列对应的扫描路径 | ||
| state | 状态 | 系统自动计算,无需配置 | |
| metaSource | 元数据来源 | ||
| publishCount | 发布总次数 | ||
| platformVersion | 最新平台版本 | 本地与中心平台的版本对应。做远程更新时会用到 | |
| publishedVersion | 最新发布版本 |
2、UeModule
是对ModuleDefinition的继承,并扩展了跟前端交互相关的元数据
| 元素数据构成 | 含义 | 对应注解 | 备注 |
|---|---|---|---|
| homePageModel | 跳转模型编码 | @UxHomepage( @UxRoute( ) ) | 对应一个ViewAction,如果UxRoute只配置了模型,则默认到该模型的列表页 |
| homePageName | 视图动作或者链接动作名称 | ||
| logo | 图标 | @UxAppLogo (logo="") |
三、模块生命周期
(一)生命周期大图
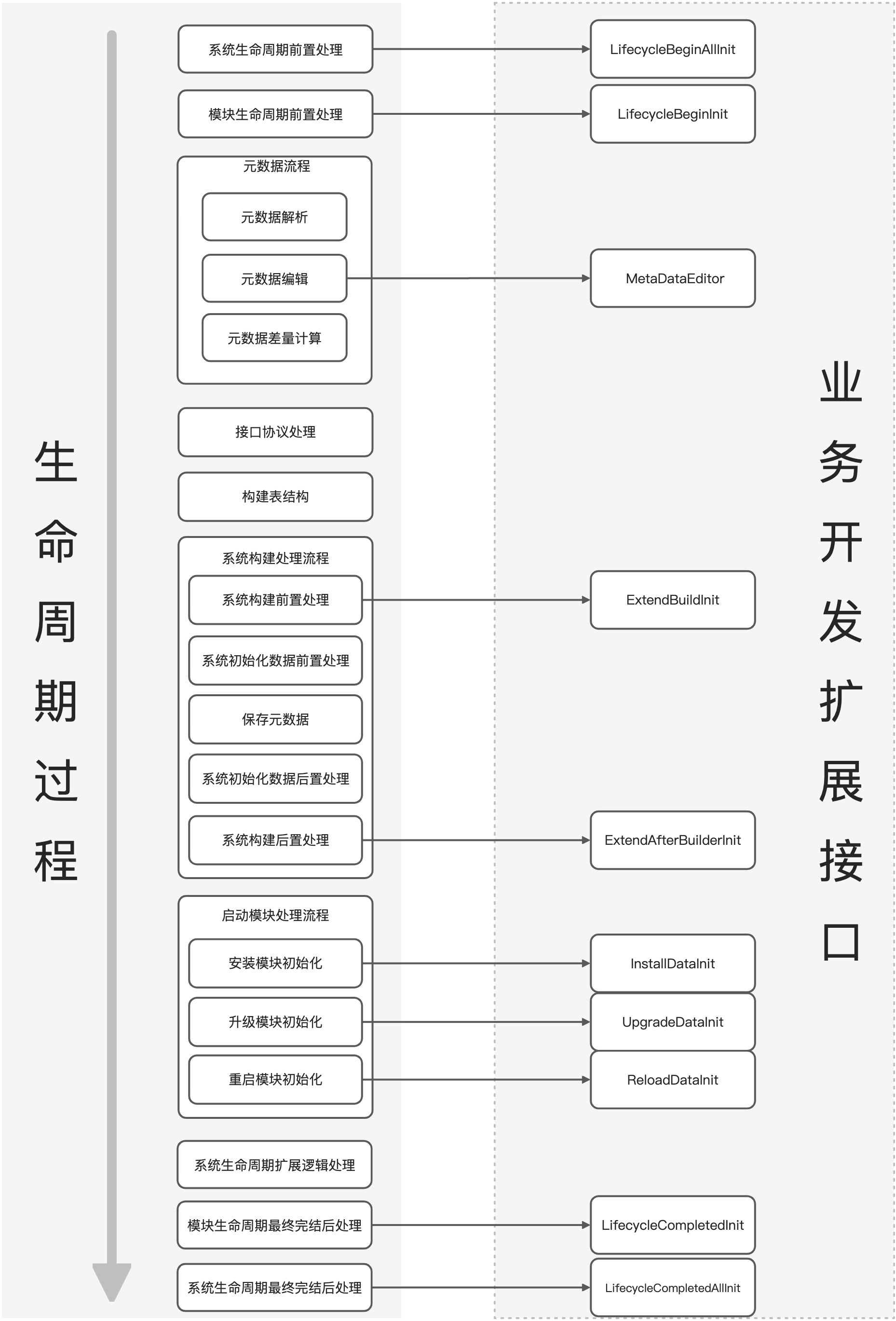
(二)业务扩展说明
| 接口 | 说明 | 使用场景 |
|---|---|---|
| LifecycleBeginAllInit | 系统进入生命周期前置逻辑 注:不能有任何数据库操作 | 系统级别的信息收集上报 |
| LifecycleCompletedAllInit | 系统生命周期完结后置逻辑 | 系统级别的信息收集上报、 生命周期过程中的数据或上下文清理 |
| LifecycleBeginInit | 模块进入生命周期前置逻辑 注:不能有任何数据库操作 | 预留,能做的事情比较少 |
| LifecycleCompletedInit | 模块生命周期完结后置逻辑 | 本模块需等待其他模块初始化完毕以后进行初始化的逻辑。 比如: 1.集成模块的初始化 2.权限缓存的初始化 …… |
| MetaDataEditor | 元数据编辑 注:不能有任何数据库操作 | 这个再初级教程中已经多次提及,核心场景是想系统主动注册如Action、Menu、View等元数据 |
| ExtendBuildInit | 系统构建前置处理逻辑 | 预留,能做的事情比较少,做一些跟模块无关的事情 |
| ExtendAfterBuilderInit | 系统构建后置处理逻辑 | 预留,能做的事情比较少,做一些跟模块无关的事情 |
| InstallDataInit | 模块在初次安装时的初始化逻辑 | 根据模块启动指令来进行选择执行逻辑,一般用于初始化业务数据。 |
| UpgradeDataInit | 模块在升级时的初始化逻辑 注:根据启动指令来执行,是否执行一次业务自己控制 | |
| ReloadDataInit | 模块在重启时的初始化逻辑 注:根据启动指令来执行,是否执行一次业务自己控制 |
四、模块启动
(一)启动工程
模块的启动工程通常与模块工程相互独立,作为单独的工程存在。它承担着将各个不同模块进行组织与组装,实现协同启动的重要职责。

各模块的boot工程与core工程彼此独立、互不依赖。其中,boot工程依赖core工程与api工程,core工程则依赖api工程。不同模块的api工程允许相互依赖,若出现循环引用情况,可通过抽取公共api工程予以解决。
Oinone可以做到,单体部署和分布式部署的灵活切换,为企业业务的发展提供了便利,同时适用于不同规模的公司,有助于有效地节约企业成本,提升创新效率,并让互联网技术更加亲民。
警告
在 Oinone 中,跨模块的存储模型若存在继承关系,部署时必须确保与依赖模块配置相同的数据源。这一特性对模块规划提出要求,例如,针对业务层面的 user 扩展模块,为保障数据一致性与功能完整性,需与 user 模块部署在一起。
(二)部署参数 pamirs.boot
在 Oinone 中,设置启动参数提供两种便捷方式:
- 命令行配置:通过
java -jar <your jar name>.jar -P参数=X的形式,可快速完成参数设定,如:-Plifecycle=INSTALL; - YAML 文件配置:利用启动 YAML 文件中的
pamirs.boot属性,实现参数的灵活配置。
当两种方式同时设置同一参数时,命令行参数将优先生效,以此确保配置的即时性与优先级 。
1、命令行配置
| 参数 | 名称 | 默认值 | 说明 |
|---|---|---|---|
| -Plifecycle | 生命周期部署指令 | INSTALL | 可选项: + INSTALL + CUSTOM_INSTALL + PACKAGE + RELOAD + DDL |
| -PbuildTable | 自动构建表结构的方式 | 无 | 可选项: + NEVER(不自动构建表结构) + EXTEND(增量构建表结构) + DIFF(差量构建表结构) |
| -PenableRpc | 是否开启远程服务 | 无 | 可选项: + true + false |
| -PopenApi | 是否开启HTTP API服务 | 无 | 可选项: + true + false |
| -PinitData | 是否开启数据初始化服务 | 无 | 可选项: + true + false |
| -PgoBack | 设置Jar版本依赖校验:当配置为true时,可实现 Jar 依赖版本降级,提升部署灵活性。 | 无 | 可选项: + true + false |
2、命令行与配置项的对照
-Plifecycle:生命周期部署指令
| 启动配置项 | 默认值 | RELOAD | INSTALL | CUSTOM_INSTALL | PACKAGE | DDL |
|---|---|---|---|---|---|---|
| pamirs.boot.install | AUTO | READONLY | AUTO | AUTO | AUTO | AUTO |
| pamirs.boot.upgrade | AUTO | READONLY | FORCE | FORCE | FORCE | FORCE |
| pamirs.boot.profile | CUSTOMIZE | READONLY | AUTO | CUSTOMIZE | PACKAGE | DDL |
-PbuildTable:自动构建表结构的方式
| 启动配置项 | 默认值 | NEVER | EXTEND | DIFF |
|---|---|---|---|---|
| pamirs.boot.option.diffTable | true | false | false | true |
| pamirs.boot.option.rebuildTable | true | false | true | true |
-PenableRpc:是否开启远程服务
| 启动配置项 | 默认值 | false | true |
|---|---|---|---|
| pamirs.boot.option.publishService | true | false | true |
-PopenApi:是否开启HTTP API服务
| 启动配置项 | 默认值 | false | true |
|---|---|---|---|
| pamirs.boot.option.rebuildHttpApi | true | false | true |
-PinitData:是否开启数据初始化服务
| 启动配置项 | 默认值 | false | true |
|---|---|---|---|
| pamirs.boot.option.updateData | true | false | true |
-PgoBack:设置Jar版本依赖校验
| 启动配置项 | 默认值 | false | true |
|---|---|---|---|
| pamirs.boot.option.goBack | false | false | true |
3、启动配置项:
Oinone 的启动配置入口为 Java 类pro.shushi.pamirs.boot.orm.configure.BootConfiguration。所有配置路径均以pamirs.boot为前缀,核心配置项涵盖:
install:安装相关配置; 启动模块列表中存在未安装模块,是否自动安装,可选值:auto | readonlyupgrade:升级相关配置;可选值: auto | force | readonly
| 可选值 | 含义 |
|---|---|
| auto | 自动升级-若模块版本号变高,则进行升级 |
| force | 强制升级-无论模块版本号有无变化,都进行升级 |
| readonly | 只读 |
profile:可选项配置组;options:自定义可选项配置;modules:模块加载配置;noCodeModule:无代码模块配置。
profile与options的对照
在 Oinone 中,若未通过命令行设置的启动参数,仅当启动 YAML 文件的pamirs.boot.profile属性值为CUSTOMIZE时,pamirs.boot.options下自定义的可选项才会生效。
| 可选项 | 说明 | 默认值 | AUTO | READONLY | PACKAGE | DDL |
|---|---|---|---|---|---|---|
| pamirs.boot.option.reloadModule | 是否加载存储在数据库中的模块信息 | false | true | true | true | true |
| pamirs.boot.option.checkModule | 校验依赖模块是否安装 | false | true | true | true | true |
| pamirs.boot.option.loadMeta | 是否扫描包读取模块元数据 | true | true | false | true | true |
| pamirs.boot.option.reloadMeta | 是否加载存储在数据库中元数据 | false | true | true | true | true |
| pamirs.boot.option.computeMeta | 是否重算元数据 | true | true | false | true | true |
| pamirs.boot.option.editMeta | 编辑元数据,是否支持编程式编辑元数据 | true | true | false | true | true |
| pamirs.boot.option.diffMeta | 差量减计算元数据 | false | true | false | true | false |
| pamirs.boot.option.refreshSessionMeta | 刷新元数据缓存 | true | true | true | true | true |
| pamirs.boot.option.rebuildHttpApi | 刷新重建前后端协议 | true | true | true | false | false |
| pamirs.boot.option.diffTable | 差量追踪表结构变更 | false | true | false | true | false |
| pamirs.boot.option.rebuildTable | 更新重建表结构 | true | true | false | true | false |
| pamirs.boot.option.printDDL | 打印重建表结构DDL | false | false | false | false | true |
| pamirs.boot.option.publishService | 发布服务,是否发布远程服务 | true | true | true | false | false |
| pamirs.boot.option.updateData | 初始化与更新内置业务数据,是否将内置业务数据的变更写入数据库 | true | true | false | true | false |
| pamirs.boot.option.params | 扩展参数 | 可自定义 | 可自定义 | 可自定义 | 可自定义 | 可自定义 |
常见问题:无DDL权限
举例:管理规范有冲突:在配备专业 DBA 团队的企业中,出于数据安全与管理规范考量,线上环境严格禁止直接执行 DDL 操作权限。
- 通过配置启动自定义可选项:pamirs.boot.options.rebuildTable为false彻底关闭自动建表功能。
pamirs:
boot:
options:
rebuildTable: false举例
- 或配置pamirs.persistence配置项来关闭部分数据源的自动建表功能。persistence配置既可以针对全局也可以分数据源进行配置。
pamirs:
persistence:
global:
# 是否自动创建数据库的全局配置,默认为true
autoCreateDatabase: true
# 是否自动创建数据表的全局配置,默认为true
autoCreateTable: true
<your ds key>:
# 是否自动创建数据库的数据源配置,默认为true
autoCreateDatabase: true
# 是否自动创建数据表的数据源配置,默认为true
autoCreateTable: true举例
- 通过-Plifecycle=DDL,即用DDL模式把涉及到数据库的变更脚本进行输出,交由公司DBA审批,并执行
modules 低代码模块启动列表
通过启动模块列表,可指定 boot 工程启动时需加载的模块。若模块分布于不同 boot 工程,其相互调用将自动触发远程通信流程,确保跨工程交互的正常运行。示例如下:
pamirs:
boot:
modules:
- base
- common
- sequence
- resource
- user
- auth
- message
- international
- business
- expensesnoCodeModule 无代码模块启动配置
pamirs:
boot:
noCodeModule:
init: true # 启动是否加载无代码模块. 默认安装. 页面新增无代码模块后,下次启动会被加载
modules: # 启动无代码模块列表
- nocodeModule1
- nocodeModule2(三)框架配置项 pamirs.framework
Oinone 框架的核心配置项按功能模块分类如下:
1、GraphQL 网关配置(pamirs.framework.gateway)
pamirs.framework.gateway.show-doc
控制是否开放 GraphQL 的 Schema 文档查询能力。设置为true时,可通过 Insomnia 等工具查看后端接口文档。
pamirs.framework.gateway.statistics
用于收集 DataLoader 运行时的状态数据,包括缓存命中次数、对象加载数量、错误次数等,辅助性能分析与问题排查。
2、Hook 函数控制配置(pamirs.framework.hook)
pamirs.framework.hook.ignoreAll
默认值false,设为true时将跳过所有 Hook 函数的执行。
pamirs.framework.hook.excludes
允许指定需排除的 Hook 函数,灵活调整 Hook 执行策略。
3、数据模块配置(pamirs.framework.data)
pamirs.framework.data.default-ds-key:
定义模块的默认数据库连接标识,需与pamirs.datasource配置中的 key 对应。
pamirs.framework.data.ds-map:
允许为特定模块指定独立数据库连接。例如,在 费用管理模块的示例场景中,若需为expenses模块配置专属数据库,可设置expenses: biz,并在pamirs.datasource中定义 key 为biz的数据源。
4、元数据系统配置(pamirs.framework.system)
pamirs.framework.system.system-ds-key:
指定元数据系统对应的数据源,需匹配pamirs.datasource配置项。
pamirs.framework.system.system-models:
标识为元数据模型,统一存储至system-ds-key对应的数据库中。
pamirs:
framework:
system:
system-ds-key: base
system-models:
- base.WorkerNode
data:
default-ds-key: pamirs
ds-map:
base: base
gateway:
statistics: true
show-doc: true
#hook 如下配置
#hook:
#excludes:
#- pro.shushi.pamirs.core.common.hook.QueryPageHook4TreeAfter
#- pro.shushi.pamirs.user.api.hook.UserQueryPageHookAfter
#- pro.shushi.pamirs.user.api.hook.UserQueryOneHookAfter(四)数据库方言 pamirs.dialect.ds
pamirs.datasource数据源方言配置说明
- 功能描述:用于定义数据源的数据库方言信息,每个配置项以唯一
key作为标识。 - 核心子参数
type:指定数据库类型,默认值为MySQL,支持替换为其他数据库类型(如 PostgreSQL、Oracle 等)。version:定义数据库版本号,默认值为8.0,需与实际数据库版本保持一致。majorVersion:指定数据库主版本号,默认值为8,用于区分不同大版本的语法特性。
- 配置示例
pamirs:
dialect: #MySQL8.0可不配置
ds:
base: # pamirs.datasource中数据源的方言信息,以key为对应
type: MySQL
version: 8.0
majorVersion: 8
pamirs: # pamirs.datasource中数据源的方言信息,以key为对应
type: MySQL
version: 8.0
majorVersion: 8更多方言配置参考:数据库方言配置专题
(五)数据源配置 pamirs.datasource
在应用程序开发与部署过程中,数据的存储与交互是至关重要的环节。pamirs.datasource 作为一个核心配置项,主要用于配置安装模块所需要的数据源信息。它为应用程序与数据库之间搭建了一座桥梁,使得应用程序能够根据不同的业务需求,稳定、高效地连接和操作数据库。通过该配置,我们可以对多个数据源进行独立设置,满足不同模块对数据库连接的差异化需求,进而提升系统的灵活性和可扩展性。
1、通用配置项
在 pamirs.datasource 下,每个数据源都有一系列通用的配置项,这些配置项决定了数据源的基本属性和连接池的行为。以下是对这些配置项的详细解释:
driverClassName:指定数据库的 JDBC 驱动类。不同的数据库需要使用不同的驱动类,例如 MySQL 使用com.mysql.cj.jdbc.Driver,Oracle 使用oracle.jdbc.OracleDriver等。该配置项确保应用程序能够正确加载并使用相应的数据库驱动。type:定义连接池的类型。常见的连接池有 HikariCP、Druid 等,在示例中使用的是com.alibaba.druid.pool.DruidDataSource,即阿里巴巴的 Druid 连接池。连接池的作用是管理数据库连接,提高连接的复用性和性能。url:数据库的连接 URL,包含了数据库的地址、端口、数据库名以及一些连接参数。例如jdbc:mysql://127.0.0.1:3306/trutorials_base?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true中,127.0.0.1是数据库的 IP 地址,3306是端口号,trutorials_base是数据库名,后面的参数则是一些连接选项,如是否使用 SSL、字符编码、时区等。username和password:用于数据库认证的用户名和密码,确保只有授权的用户能够访问数据库。initialSize:连接池的初始化连接数,即应用程序启动时,连接池会预先创建的数据库连接数量。合适的初始大小可以减少应用程序启动后首次访问数据库时的等待时间。maxActive:连接池的最大活跃连接数,即连接池中允许同时存在的最大连接数量。当应用程序需要的连接数超过这个限制时,新的请求将等待直到有连接被释放。minIdle:连接池的最小空闲连接数,即连接池中始终保持的最小空闲连接数量。当连接池中的空闲连接数低于这个值时,连接池会自动创建新的连接。maxWait:获取连接时的最大等待时间(毫秒)。如果在这个时间内无法获取到连接,将抛出异常。该配置项可以避免应用程序长时间等待连接,提高系统的响应性能。timeBetweenEvictionRunsMillis:配置间隔多久才进行一次检测,检测需要关闭的空闲连接(毫秒)。通过定期检测,可以及时释放长时间闲置的连接,减少资源占用。testWhileIdle:申请连接时检测连接是否有效。如果设置为true,在从连接池中获取连接时,会先检查连接是否可用,避免获取到无效的连接。testOnBorrow:借出连接时检测连接是否有效。与testWhileIdle不同,该配置项是在每次从连接池中获取连接时进行检测,会增加一定的性能开销。testOnReturn:归还连接时检测连接是否有效。设置为true时,在将连接归还到连接池时会进行有效性检测,确保连接池中的连接都是可用的。poolPreparedStatements:是否缓存PreparedStatement。PreparedStatement是一种预编译的 SQL 语句,缓存它可以提高 SQL 执行的性能。asyncInit:是否异步初始化连接池。设置为true时,连接池的初始化将在后台线程中进行,不会阻塞应用程序的启动。
2、多数据源配置
pamirs.datasource 支持配置多个数据源,每个数据源通过一个唯一的名称进行标识,例如示例中的 pamirs 和 base。这样可以满足不同模块对不同数据库的访问需求,例如一个模块可能需要访问业务数据库,另一个模块可能需要访问日志数据库。通过独立配置每个数据源的连接信息,可以确保各个模块之间的数据访问互不干扰。
3、配置示例
以下 YAML 示例展示了两个数据源(pamirs 和 base)的完整配置,均采用阿里巴巴 Druid 连接池连接 MySQL 数据库:
pamirs:
datasource:
pamirs:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/trutorials_pamirs?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
initialSize: 5
maxActive: 200
minIdle: 5
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
asyncInit: true
base:
driverClassName: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/trutorials_base?useSSL=false&allowPublicKeyRetrieval=true&useServerPrepStmts=true&cachePrepStmts=true&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&autoReconnect=true&allowMultiQueries=true
username: root
password: oinone
initialSize: 5
maxActive: 200
minIdle: 5
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
asyncInit: true在实际应用中,可根据业务需求调整数据源名称、连接参数及连接池配置,灵活适配不同数据库环境。例如,如果需要连接 PostgreSQL 数据库,只需将 driverClassName 改为 org.postgresql.Driver,并修改 url 为相应的 PostgreSQL 连接地址即可。同时,根据数据库的性能和应用程序的负载情况,合理调整连接池的参数,如 initialSize、maxActive 等,可以进一步优化系统的性能。
(六)分库分表配置 pamirs.sharding
pamirs.sharding是 Oinone 框架中用于实现分库分表的核心配置模块,主要用于定义数据库的水平拆分策略与映射规则。当使用pamirs-trigger-bridge-tbschedule工程开启内置调度功能时,该配置为必选项,它能够有效应对高并发场景下的数据存储与访问压力,提升系统的扩展性和性能表现。通过该配置,开发者可灵活指定数据源映射关系、数据模型的分表规则以及分库分表的具体策略,实现数据在多个数据库与表之间的合理分布。
1、核心配置结构解析
define:基础定义模块
data-sources:用于声明数据源的映射关系。- 单数据源映射:如
ds: pamirs和pamirsSharding: pamirs,表示将逻辑数据源ds和pamirsSharding关联至实际数据源pamirs。 - 多数据源映射:如
testShardingDs,将逻辑数据源testShardingDs映射到物理数据源列表testShardingDs_0和testShardingDs_1,支持动态数据读写分发。
- 单数据源映射:如
models:定义数据模型的分表规则。- 示例中
[trigger.PamirsSchedule]模型通过tables: 0..13配置,表明该模型对应 14 张物理表; [demo.ShardingModel]模型除分表规则外,还通过table-separator: _指定表名分隔符;[demo.ShardingModel2]模型同时定义了ds-nodes: 0..1(分库规则)和ds-separator: _(库名分隔符),实现库表双重拆分。
- 示例中
rule:分库分表规则模块
针对每个逻辑数据源,通过rule子项配置具体的分库分表策略,配置语法与 Sharding-JDBC 高度兼容:
actual-ds:明确逻辑数据源对应的实际物理数据源列表,确保数据读写定位准确。sharding-rules:定义表级分库分表规则,包含:actualDataNodes:指定数据实际存储的库表组合(如pamirs.demo_core_sharding_model_${0..7});tableStrategy/databaseStrategy:配置分表 / 分库的分片策略,通过shardingColumn指定分片键,shardingAlgorithmName关联具体分片算法;shardingAlgorithms:定义分片算法实现,如INLINE类型通过algorithm-expression表达式计算目标库表(如demo_core_sharding_model_${(Long.valueOf(user_id) % 8)}表示按user_id取模分配至 8 张表)。
replica-query-rules:定义主从读写规则,包含:- 数据源定义(
data-sources)pamirsSharding:数据源组名称,可自定义。primaryDataSourceName:指定主库数据源(用于写操作)。replicaDataSourceNames:从库数据源列表(用于读操作,支持多节点)。loadBalancerName:引用load-balancers中定义的负载均衡策略。
- 负载均衡策略(
load-balancers)round_robin:负载均衡器名称,需与loadBalancerName一致。type: ROUND_ROBIN:采用轮询算法分配读请求,确保从库负载均衡。
- 数据源定义(
props:全局属性配置,如sql.show: true开启 SQL 执行日志打印,便于调试和性能分析。
2、配置示例
分库分表配置示例
pamirs:
sharding:
define:
data-sources:
ds: pamirs
pamirsSharding: pamirs #申明pamirsSharding库对应的pamirs数据源
testShardingDs: #申明testShardingDs库对应的testShardingDs_0\1数据源
- testShardingDs_0
- testShardingDs_1
models:
"[trigger.PamirsSchedule]":
tables: 0..13
"[demo.ShardingModel]":
tables: 0..7
table-separator: _
"[demo.ShardingModel2]":
ds-nodes: 0..1 #申明testShardingDs库对应的建库规则
ds-separator: _
tables: 0..7
table-separator: _
rule:
pamirsSharding: #配置pamirsSharding库的分库分表规则
actual-ds:
- pamirs #申明pamirsSharding库对应的pamirs数据源
sharding-rules:
# Configure sharding rule,以下配置跟sharding-jdbc配置一致
- tables:
demo_core_sharding_model:
actualDataNodes: pamirs.demo_core_sharding_model_${0..7}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
table_inline:
type: INLINE
props:
algorithm-expression: demo_core_sharding_model_${(Long.valueOf(user_id) % 8)}
props:
sql.show: true
testShardingDs: #配置testShardingDs库的分库分表规则
actual-ds: #申明testShardingDs库对应的pamirs数据源
- testShardingDs_0
- testShardingDs_1
sharding-rules:
# Configure sharding rule,以下配置跟sharding-jdbc配置一致
- tables:
demo_core_sharding_model2:
actualDataNodes: testShardingDs_${0..1}.demo_core_sharding_model2_${0..7}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: ds_inline
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
table_inline:
type: INLINE
props:
algorithm-expression: demo_core_sharding_model2_${(Long.valueOf(user_id) % 8)}
ds_inline:
type: INLINE
props:
algorithm-expression: testShardingDs_${(Long.valueOf(user_id) % 2)}
props:
sql.show: true根据业务需求灵活调整数据源映射、分片策略及算法表达式,实现高效的数据分片管理。
主从读写规则配置示例
pamirs:
sharding:
define:
data-sources:
pamirsSharding: pamirsMaster # 为逻辑数据源pamirsSharding指向主数据源pamirsMaster。
models:
"[trigger.PamirsSchedule]":
tables: 0..13
rule:
pamirsSharding:
actual-ds: # 指定逻辑数据源pamirsSharding代理的数据源为pamirsMaster、pamirsSlaver
- pamirsMaster
- pamirsSlaver
# 以下配置跟sharding-jdbc配置一致
replicaQueryRules:
data-sources:
pamirsSharding:
primaryDataSourceName: pamirsMaster # **写库数据源**:主库名称
replicaDataSourceNames:
- pamirsSlaver # **读库数据源列表**:从库名称(支持多从库)
loadBalancerName: round_robin # **负载均衡器引用**:关联负载均衡策略名称
load-balancers:
round_robin:
type: ROUND_ROBIN # **负载均衡类型**:轮询策略(读请求均匀分配至从库)应用场景
- 读写分离:写操作路由至
pamirsMaster,读操作通过轮询分发至pamirsSlaver(可扩展多个从库)。 - 高可用性:通过负载均衡策略提升读操作性能,避免单从库压力过大。
扩展说明
- 若需新增从库,直接在
replicaDataSourceNames列表中添加数据源名称即可。 - 支持切换负载均衡类型(如
RANDOM随机策略),只需修改type字段值。
(七)库表映射规则 pamirs.mapper
1、库配置
在 pamirs.mapper 中,可借助 YAML 里的 “pamirs.mapper.<global或者ds>” 配置项对数据库进行相关配置。若未进行配置,系统会自动采用默认值。具体配置项、默认值及描述如下表所示:
| 配置项 | 默认值 | 描述 |
|---|---|---|
databaseFormat | %s | 库名格式化规则,%s会被实际库名替换 |
tableFormat | %s | 表名格式化规则,%s会被实际表名替换 |
tablePattern | ${moduleAbbr}_%s | 动态表名表达式,用于灵活生成表名,%s会被实际表名替换 |
columnPattern | %s | 列名格式化规则, %s会被实际列名替换 |
tableNameCaseSensitive | false | 表名区分大小写,为false时,会自动执行toLowerCase转换为全小写,为true时可指定具有大小写格式的表名。 |
2、表配置
表配置可通过两种方式实现:一是使用 YAML 的 “pamirs.mapper.<global或者ds>.table-info” 配置项;二是使用 @Model.Persistence 注解。需要注意的是,注解的优先级高于 YAML 配置文件的配置。若未进行配置,系统会使用默认值。具体配置项、默认值及描述如下:
| 配置项 | 默认值 | 描述 |
|---|---|---|
logicDelete | true | 是否采用逻辑删除方式,true表示开启,false表示关闭 |
logicDeleteColumn | is_delete | 逻辑删除所使用的字段名 |
logicDeleteValue | REPLACE(unix_timestamp(NOW(6)),'.','') | 逻辑删除时该字段所赋予的值 |
logicNotDeleteValue | 0 | 非逻辑删除时该字段的值 |
optimisticLocker | false | 是否开启乐观锁机制,true为开启,false为关闭 |
optimisticLockerColumn | opt_version | 乐观锁所使用的字段名 |
keyGenerator | AUTO_INCREMENT | 主键自增的规则 |
underCamel | true | 是否开启驼峰与下划线的转换,true表示开启转换 |
capitalMode | false | 是否进行大小写转换,true表示开启转换,只有开启了tableNameCaseSensitive属性后才会生效。 |
columnFormat | %s | 列名的格式化规则,%s会被实际列名替换 |
aliasFormat | %s | 字段别名的格式化规则,%s会被实际字段别名替换 |
charset | utf8mb4 | 所使用的字符集 |
collate | bin | 排序所使用的字符集 |
3、批量操作配置
批量操作支持批量创建和批量更新,系统默认的提交类型为 batchCommit。以下是四种提交类型的详细说明:
useAffectRows
- 提交方式:循环执行单次单条脚本提交(逐条处理)。
- 特性:
- 每条操作独立执行,返回实际影响的行数(如更新成功的记录数)。
- 适用于需要精确跟踪每条操作结果的场景(如逐条审计)。
useAndJudgeAffectRows
- 提交方式:同样采用循环单次单条脚本提交。
- 特性:
- 除返回实际影响行数外,会自动校验返回值与输入的预期行数是否一致。
- 若不一致(如预期更新 1 条但实际影响 0 条),立即抛出异常,终止后续操作。
- 适合对数据一致性要求极高的场景(如金融交易、库存扣减)。
collectionCommit
- 提交方式:将多个单条更新脚本拼接成一个复合脚本提交(如拼接多条
UPDATE语句)。 - 特性:
- 仅支持批量更新,无法返回每条操作的实际影响行数(仅返回总操作是否成功)。
- 减少数据库交互次数,提升性能,但牺牲结果细节。
batchCommit(默认值)
- 提交方式:使用数据库支持的单条批量操作脚本(如参数化批量语句)提交。
- 特性:
- 支持批量创建和更新,通过一次数据库交互完成多数据操作。
- 不返回实际影响行数,仅确认操作是否整体成功。
- 性能最优,适用于无需逐条结果反馈的常规批量操作。
| 提交类型 | 执行方式 | 返回结果 | 性能 | 适用场景 |
|---|---|---|---|---|
useAffectRows | 逐条执行 | 单条影响行数 | 最低(N 次交互) | 精细结果追踪 |
useAndJudgeAffectRows | 逐条执行 + 结果校验 | 单条影响行数(异常中断) | 低(N 次交互) | 强一致性场景 |
collectionCommit | 脚本拼接一次性提交 | 整体成功 / 失败 | 中(1 次交互) | 批量更新(非严格结果要求) |
batchCommit | 数据库原生批量语句提交 | 整体成功 / 失败 | 最高(1 次交互) | 常规批量操作(默认推荐) |
4、配置示例
pamirs:
mapper:
static-model-config-locations:
- pro.shushi.pamirs
batch: batchCommit
batch-config:
"[base.Field]":
write: 2000
"[base.Function]":
read: 500
write: 2000
global: # 全局配置
table-info:
logic-delete: true
logic-delete-column: is_deleted
logic-delete-value: REPLACE(unix_timestamp(NOW(6)),'.','')
logic-not-delete-value: 0
optimistic-locker: false
optimistic-locker-column: opt_version
key-generator: DISTRIBUTION
table-pattern: '${moduleAbbr}_%s'
ds:
biz: # 单个数据源配置,优先级高
table-info:
# 跟全局一样的配置可以不用重复配置
logic-delete: true
logic-delete-column: is_deleted
logic-delete-value: REPLACE(unix_timestamp(NOW(6)),'.','')
optimistic-locker: false
optimistic-locker-column: opt_version
# ID生成方式:1、DISTRIBUTION:分布式ID;2、AUTO_INCREMENT:自增ID
key-generator: AUTO_INCREMENT
table-pattern: '${moduleAbbr}_%s'(八)数据持久层配置 pamirs.persistence
pamirs.persistence 是 Oinone 框架中实现自动化数据持久化管理的核心配置项,支持自动创建数据库与数据表。
1、核心配置项
pamirs.persistence 支持 全局与数据源级 两种配置层级,具体如下:
全局配置(global)
适用于所有数据源的统一规则设定,关键参数:
autoCreateDatabase:控制是否全局自动创建数据库,默认值为true。启用后,系统将根据配置自动生成数据库实例。autoCreateTable:控制是否全局自动创建数据表,默认值为true。开启后,系统会依据数据模型定义,自动生成对应的数据表结构。
数据源级配置(<your ds key>)
针对特定数据源进行独立配置,优先级高于全局配置,可实现差异化管理:
autoCreateDatabase:针对指定数据源设置是否自动创建数据库,默认值true。用于覆盖全局规则,满足部分数据源无需自动建库的需求。autoCreateTable:针对指定数据源设置是否自动创建数据表,默认值true。支持单独控制数据表的自动化创建,适配复杂业务场景。
2、配置示例
pamirs:
persistence:
global:
# 是否自动创建数据库的全局配置,默认为true
autoCreateDatabase: true
# 是否自动创建数据表的全局配置,默认为true
autoCreateTable: true
<your ds key>:
# 是否自动创建数据库的数据源配置,默认为true
autoCreateDatabase: true
# 是否自动创建数据表的数据源配置,默认为true
autoCreateTable: true通过上述配置,可灵活组合全局与局部规则,兼顾效率与灵活性,确保数据库资源按需自动化部署,同时降低误操作风险。
(九)事件配置 pamirs.event
1、核心配置
pamirs.event 用于管理系统事件消息的基础配置与分发策略,具体配置如下:
pamirs:
event:
enabled: true # 全局控制event功能的启用状态,默认为true,true为开启,false为关闭
topic-prefix: oinone # 所有事件主题的统一前缀,便于主题名称的规范化管理
notify-map:
system: ROCKETMQ # 系统消息的消息队列类型,可选择ROCKETMQ、KAFKA或RABBITMQ
biz: ROCKETMQ # 业务消息的消息队列类型,可选择ROCKETMQ、KAFKA或RABBITMQ
logger: ROCKETMQ # 日志消息的消息队列类型,可选择ROCKETMQ、KAFKA或RABBITMQ
schedule:
enabled: true # trigger开关 默认为true
#ownSign: demo # 事件隔离健,确保两组机器只取各自产生的数据通过上述配置,可灵活指定不同类型消息(系统、业务、日志)的队列载体,并通过 topic-prefix 实现消息主题的统一命名规范,同时利用 enabled 开关快速启停事件功能。
2、消息队列连接配置
系统支持 RocketMQ、Kafka、RabbitMQ 三种消息队列,其连接及参数配置示例如下:
RocketMQ 配置
spring:
rocketmq:
name-server: 127.0.0.1:9876 # RocketMQ NameServer地址,用于生产者与消费者定位集群
producer:
enableMsgTrace: true # 开启消息轨迹追踪功能,便于排查消息发送问题
customizedTraceTopic: TRACE_PRODUCER # 自定义消息轨迹主题
consumer:
enableMsgTrace: true # 开启消费者端消息轨迹追踪
customizedTraceTopic: TRACE_CONSUMER # 消费者端自定义轨迹主题Kafka 配置
spring:
kafka:
bootstrap-servers: localhost:9092 # Kafka集群地址,用于建立连接
producer:
value-serializer: pro.shushi.pamirs.framework.connectors.event.kafka.marshalling.PamirsKafkaMarshalling # 消息序列化类,用于将消息转换为字节流
consumer:
group-id: ${spring.application.name} # 消费者组ID,同一组内消费者共同消费Topic分区
value-deserializer: pro.shushi.pamirs.framework.connectors.event.kafka.marshalling.PamirsKafkaMarshalling # 消息反序列化类,用于解析字节流为消息对象RabbitMQ 配置
spring:
rabbitmq:
host: 127.0.0.1 # RabbitMQ服务器主机地址
port: 5672 # 服务端口号
username: oinone # 登录用户名
password: oinone # 登录密码
listener:
direct:
acknowledge-mode: manual # 消息确认模式设为手动确认,确保消息被正确处理后再确认,避免丢失以上配置需根据实际环境调整地址、端口、认证信息等参数,通过 pamirs.event.notify-map 与消息队列配置的联动,实现不同类型消息的高效分发与可靠传输。
(十)数据记录配置 pamirs.record.sql
在使用 pamirs 框架的 SQL 记录功能时,可通过如下配置指定 SQL 日志文件的存储位置。该配置允许你将系统执行的 SQL 语句及其相关信息记录到特定目录
pamirs:
record:
sql:
# 此路径用于指定 SQL 日志文件的存储目录,可根据实际需求修改
store: /oinone/sql/record你可按需修改 store 字段为合适的本地或远程存储路径。若未配置,默认取 System.getProperty("user.dir") 即用户所在目录。
(十一)元数据路径配置 pamirs.meta
pamirs.meta 用于配置元数据相关的路径信息,其中核心配置项 views-package 用于指定模板文件的存储后缀。具体说明如下:
views-package:定义模板文件的默认路径后缀,默认值为/pamirs/views。若需自定义视图文件路径,可按约定采用/pamirs/views/X格式(X为模块编码,,无需在路径中手动指定),自定义路径优先级高于默认配置,即系统优先读取自定义路径下的模板文件。
meta:
# 模板文件后缀,默认值为:/pamirs/views
views-package: /pamirs/views(十二)增强模型配置 pamirs.channel
EnhanceModel 增强模型为系统赋予了强大的全文检索能力。若要使用该功能,你需要对扫描路径、搜索引擎相关参数进行配置,同时此功能依赖 pamirs.event 事件配置。
1、扫描路径配置
在 pamirs.channel.packages 中指定需要扫描的包路径,若增强模型的定义类不在 pro.shushi.pamirs 包下,则必须进行此项配置。示例如下:
pamirs:
channel:
packages:
- xx.xx.xx # 扫描增强模型 定义类在非pro.shushi.pamirs包下需要配置2、搜索引擎配置
使用 Elasticsearch 作为搜索引擎时,需在 pamirs.elastic 中配置其连接地址。示例如下:
pamirs:
elastic:
url: 127.0.0.1:9200注意
EnhanceModel 增强模型功能依赖 pamirs.event 事件配置,请确保该事件配置已正确设置,以保障增强模型的正常运行。
(十三)授权文件配置 pamirs.license
在使用 Oinone 企业版时,为确保系统正常运行,你需要对授权文件进行配置。具体配置如下:
pamirs:
license:
#改成平台提供证书的路径以及subject
path: licence/oinone-demo.lic
subject: oinone-demo请依据平台提供的实际信息,准确修改 path 和 subject 的值。path 需指定证书文件的存储路径,subject 则是证书的标识信息。只有完成正确配置,才能顺利使用 Oinone 企业版的各项功能。
(十四)文件存储配置 pamirs.file
Oinone 目前支持多种类型的 OSS 服务,以满足不同用户的存储需求。以下是详细介绍:
1、支持的 OSS 类型
| 类型 | 服务 |
|---|---|
| OSS | 阿里云 OSS |
| UPYUN | 又拍云 |
| MINIO | MinIO |
| HUAWEI_OBS | 华为云 OBS |
| LOCAL | 本地 NGINX 文件存储 |
| TENCENT_COS | 腾讯云 COS |
2、OSS 通用 YAML 配置
cdn:
oss:
name: # 名称
type: # 类型
bucket:
uploadUrl: # 上传 URL
downloadUrl: # 下载 URL
accessKeyId:
accessKeySecret:
mainDir: # 主目录
validTime: 3600000
timeout: 600000
active: true
referer:
localFolderUrl:
others:
[key]:
name: # 名称
type: # 类型
bucket:
uploadUrl: # 上传 URL
downloadUrl: # 下载 URL
accessKeyId:
accessKeySecret:
mainDir: # 主目录
validTime: 3600000
timeout: 600000
active: true
referer:
localFolderUrl:注意:others 中使用自定义 key 来指定 OSS 服务进行文件上传 / 下载功能,上传和下载配置必须匹配,否则无法正常使用。
3、各 OSS 配置示例
阿里云 OSS
cdn:
oss:
name: 阿里云
type: OSS
bucket: pamirs(根据实际情况修改)
uploadUrl: oss-cn-hangzhou.aliyuncs.com
downloadUrl: oss-cn-hangzhou.aliyuncs.com
accessKeyId: 你的 accessKeyId
accessKeySecret: 你的 accessKeySecret
# 根据实际情况修改
mainDir: upload/
validTime: 3600000
timeout: 600000
active: true
imageResizeParameter:
referer:华为云 OBS
cdn:
oss:
name: 华为云
type: HUAWEI_OBS
bucket: pamirs(根据实际情况修改)
uploadUrl: obs.cn-east-2.myhuaweicloud.com
downloadUrl: obs.cn-east-2.myhuaweicloud.com
accessKeyId: 你的 accessKeyId
accessKeySecret: 你的 accessKeySecret
# 根据实际情况修改
mainDir: upload/
validTime: 3600000
timeout: 600000
active: true
allowedOrigin: http://192.168.95.31:8888,https://xxxx.xxxxx.com
referer:依赖添加:使用华为云 OBS 需要在启动工程中增加以下依赖:
<okhttp3.version>4.9.3</okhttp3.version>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>${okhttp3.version}</version>
</dependency>注意事项:华为云 OBS 的防盗链配置严格,仅允许携带特定 referer 的访问,而 excel 导入后端处理逻辑在匿名读时不带 referer,会导致访问被拒绝。
MINIO
cdn:
oss:
name: minio
type: MINIO
bucket: pamirs(根据实际情况修改)
uploadUrl: http://192.168.243.6:32190(根据实际情况修改)
downloadUrl: http://192.168.243.6:9000(根据实际情况修改)
accessKeyId: 你的 accessKeyId
accessKeySecret: 你的 accessKeySecret
# 根据实际情况修改
mainDir: upload/
validTime: 3600000
timeout: 600000
active: true
referer:
localFolderUrl:无公网访问地址配置:MINIO 无公网访问地址下 OSS 的配置方式,详见 文件存储:MINIO无公网访问地址下OSS的配置。
又拍云
cdn:
oss:
name: 又拍云
type: UPYUN
bucket: pamirs(根据实际情况修改)
uploadUrl: v0.api.upyun.com
downloadUrl: v0.api.upyun.com
accessKeyId: 你的 accessKeyId
accessKeySecret: 你的 accessKeySecret
# 根据实际情况修改
mainDir: upload/
validTime: 3600000
timeout: 600000
active: true
referer:腾讯云 COS
cdn:
oss:
name: TENCENT_COS
type: TENCENT_COS
bucket: cos-dcode-prod-1252296671
uploadUrl: cos.ap-shanghai.myqcloud.com
downloadUrl: cos.ap-shanghai.myqcloud.com
accessKeyId: 你的 accessKeyId
accessKeySecret: 你的 accessKeySecret
mainDir: upload/demo/
validTime: 3600000
timeout: 600000
active: true
image-resize-parameter:
allowedOrigin: https://test.oinone.com,http://127.0.0.1:88
referer:4、OSS 配置使用示例
若后台要直接上传文件到 OSS,可通过 FileClientFactory.getClient() 获取系统配置的文件系统客户端。
// 获取文件客户端
// 1、获取默认的文件客户端
FileClient fileClient = FileClientFactory.getClient();
// 2、根据 cdnKey 获取文件客户端(多 CDN 配置下使用)
FileClient fileClient = FileClientFactory.getClient(resourceFileForm.getCdnKey());
// 示例 1
CdnFile cdnFile = FileClientFactory.getClient().upload(fileName, data/**byte[]*/);
// 示例 2
String fileName = "路径名/" + file.getName();
FileClientFactory.getClient().uploadByFileName(fileName, is/**InputStream*/);以上配置和示例可帮助您快速、准确地配置和使用 Oinone 中的 OSS 服务。
5、数据导入导出配置
pamirs:
file:
auto-upload-logo: false
import-property:
default-each-import: false # 默认逐行导入
max-error-length: 100 # 默认最大收集错误行数
export-property:
default-clear-export-style: false # 默认使用csv导出
csv-max-support-length: 1000000 # csv导出最大支持1000000行(十五)权限配置 pamirs.auth
pamirs.auth 是系统中用于精细控制权限验证的核心配置项,借助它能够灵活定制不同模型函数的权限校验规则,满足多样化的业务需求,提升系统的安全性与灵活性。
1、核心配置项说明
pamirs.auth.fun-filter
此配置项用于指定模型中的特定函数无需进行权限控制。在某些场景下,部分函数可能不需要严格的权限验证,通过该配置可以绕过权限检查,提高系统处理效率。
pamirs.auth.fun-filter-only-login
该配置项用于指定模型中的特定函数仅需验证用户是否登录。对于一些只需确保用户处于登录状态即可访问的功能,使用此配置可简化权限验证流程。
2、配置示例
pamirs:
auth:
fun-filter-only-login:
- namespace: base.ViewAction
fun: homepage #登录
fun-filter:
- namespace: user.PamirsUserTransient
fun: login #登录在上述示例中,base.ViewAction 命名空间下的 homepage 函数仅需验证用户是否登录,而 user.PamirsUserTransient 命名空间下的 login 函数则无需进行任何权限控制。开发者可根据实际业务需求,灵活调整配置内容,实现对不同函数的精准权限管理。
(十六)集成平台配置 pamirs.eip
通过配置 open-api 模块可快速启用并自定义开放接口参数,具体说明如下:
pamirs:
eip:
open-api:
enabled: true # 开启开放接口功能,false 为关闭
test: true # 启用测试模式,可用于调试接口逻辑
route:
host: 0.0.0.0 # 开放接口监听地址
port: 9091 # 开放接口监听端口
aes-key: 6/whOst2CXbxmISUBz9+ayLwmNHsgSqbrNL2xGRMfe8= # AES加密密钥,用于数据安全传输
expires: 7200 # 接口访问令牌有效期(单位:秒)
delay-expires: 300 # 令牌延迟失效时间(单位:秒)通过以上配置,可灵活控制开放接口的启用状态、网络监听参数及安全策略。enabled 与 test 开关用于快速启停功能与调试,route 下的参数则保障接口访问的安全性与时效性。
(十七)分布式缓存配置项 pamirs.distribution
Oinone 的分布式缓存配置入口为 Java 类pro.shushi.pamirs.distribution.session.config.DistributionSessionConfig。所有配置路径均以pamirs.distribution.session为前缀,核心配置项涵盖:
- allMetaRefresh
- ownSign
Oinone 的分布式缓存配置核心入口为 Java 类pro.shushi.pamirs.distribution.session.config.DistributionSessionConfig。所有配置路径均以pamirs.distribution.session为前缀,核心配置项如下:
allMetaRefresh:在分布式缓存元数据刷新策略配置中,allMetaRefresh默认值为false,系统自动启用差量更新 Redis 机制;当该配置项设为true,系统将切换至全量更新模式,确保数据完整同步。ownSign:用于设置缓存数据专属标识,保障数据唯一性与可追溯性,避免研发协同环境中本地元数据污染公共环境,并在请求 URL 含该参数时自动合并双路径缓存。
pamirs:
distribution:
session:
allMetaRefresh: true
ownSign: devUser1(十八)中间件相关配置
1、消息队列连接配置
参考:事件配置中消息队列连接配置
2、搜索引擎Elastic配置
参考:增强模型中搜索引擎配置
3、配置中心 pamirs.zookeeper
ZooKeeper 作为配置中心,用于管理和存储系统的配置信息。通过合理配置相关参数,可确保系统与 ZooKeeper 服务的稳定连接和数据交互。以下是详细的配置项说明及示例:
配置项说明
zkConnectString:ZooKeeper 服务器的连接字符串,指定了 ZooKeeper 集群的地址和端口。多个服务器地址之间使用逗号分隔。zkSessionTimeout:ZooKeeper 会话的超时时间,单位为毫秒。若在该时间内没有与 ZooKeeper 服务器进行有效的交互,会话将被关闭。rootPath:ZooKeeper 中存储配置信息的根路径,所有的配置数据将存储在该路径下。
配置示例
pamirs:
zookeeper:
zkConnectString: 127.0.0.1:2181
zkSessionTimeout: 60000
rootPath: /trutorials通过上述配置,系统将连接到本地的 ZooKeeper 服务器,并在 /trutorials 路径下管理配置信息。你可以根据实际情况修改这些配置项,以适应不同的生产环境。
4、Redis配置
Oinone 使用 Redis 时,借助 Spring 框架进行配置。以下是详细的 Redis 配置示例,你可依据实际情况灵活调整配置项。
spring:
redis:
database: 1
host: 127.0.0.1
port: 6379
timeout: 5000
# password: Abc@1234
jedis:
pool:
# 连接池中的最大空闲连接 默认8
max-idle: 16
# 连接池中的最小空闲连接 默认0
min-idle: 4
# 连接池最大连接数 默认8 ,负数表示没有限制
max-active: 16
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认-1
max-wait: 5000上述配置对 Redis 的连接信息与连接池参数进行了设置。其中,database 可指定要使用的数据库;host 和 port 用于确定 Redis 服务器的地址与端口;timeout 能避免长时间等待连接;连接池相关参数(如 max-idle、min-idle、max-active 和 max-wait)可优化 Redis 连接的使用与管理,提升系统性能。
5、RPC配置-Dubbo
Dubbo 是高性能、轻量级的开源 RPC 框架,通过以下配置可实现基于 Dubbo 的远程服务调用与管理。以下配置示例涵盖服务应用信息、注册中心、通信协议、服务消费与提供方等核心参数,可根据实际需求灵活调整:
dubbo:
application:
# 当前应用名称,用于在注册中心标识服务所属应用
name: trutorials-boot
# 当前应用版本号,便于服务版本管理与兼容性控制
version: 1.0.0
registry:
# 注册中心地址,采用 Zookeeper 作为注册中心,连接本地 2181 端口
address: zookeeper://127.0.0.1:2181
protocol:
# 通信协议采用 Dubbo 协议
name: dubbo
# 服务端口设置为 -1 时,将自动分配可用端口
port: -1
# 数据序列化方式,此处使用 pamirs 序列化方案
serialization: pamirs
consumer:
# 服务消费方调用服务的超时时间,单位为毫秒,设置为 5000 毫秒
timeout: 5000
provider:
# 服务提供方处理请求的超时时间,单位为毫秒,设置为 5000 毫秒
timeout: 5000
scan:
# 自动扫描指定包路径下的 Dubbo 服务注解,此处扫描 pro.shushi 及其子包
base-packages: pro.shushi
cloud:
subscribed-services: # 预留的订阅服务配置项,可用于配置需订阅的云服务列表警告
在 Oinone 里,统一采用专属的 pamirs 序列化方案进行序列化操作。若配置与此方案不一致,远程调用时将触发序列化异常。
(十九) 环境保护
Oinone 平台面向合作伙伴推出环境保护功能,通过严格的安全防护,保障同一环境内配置文件修改、多 JVM 启动等部署操作安全执行。
1、命令行配置
-PenvProtected=${value}
Oinone 平台的环境保护功能默认开启(默认值为 true)。该功能会将当前配置与数据库中 base_platform_environment 表所保存的最近一次数据进行比对,结合每个参数的配置特性加以判断。在系统启动时,若存在错误配置内容,会将其打印在启动日志里,方便开发者快速定位并排查问题。
此外,环境保护功能还会基于比对结果,为开发者提供生产配置方面的优化建议。开发者在启动系统时,可留意相关日志内容,进而对生产环境的配置进行优化调整。
-PsaveEnvironments=${value}
是否将此次启动的环境参数保存到数据库,默认为true。
在某些特殊情况下,为了避免公共环境中的保护参数发生不必要的变化,我们可以选择不保存此次启动时的配置参数到数据库中,这样就不会影响其他JVM启动时发生校验失败而无法启动的问题。
-PstrictProtected=${value}
是否使用严格校验模式,默认为false
通常我们建议在公共环境启用严格校验模式,这样可以最大程度的保护公共环境的元数据不受其他环境干扰。
注意
在启用严格校验模式时,需避免内外网使用不同连接地址的场景。如无法避免,则无法启用严格校验模式。
2、常见问题
需要迁移数据库,并更换了数据库连接地址该如何操作?
- 将原有数据库迁移到新数据库。
- 修改配置文件中数据库的连接地址。
- 在启动脚本中增加
-PenvProtected=false关闭环境保护。 - 启动JVM服务可以看到有错误的日志提示,但不会中断本次启动。
- 移除启动脚本中的
-PenvProtected=false或将值改为true,下次启动时将继续进行环境保护检查。 - 可查看数据库中
base_platform_environment表中对应数据库连接配置已发生修改,此时若其他JVM在启动前未正确修改,则无法启动。
本地开发时需要修改Redis连接地址到本地,但希望不影响公共环境的使用该如何操作?
PS:由于Redis中的元数据缓存是根据数据库差量进行同步的,此操作会导致公共环境在启动时无法正确刷新Redis中的元数据缓存,需要配合pamirs.distribution.session.allMetaRefresh参数进行操作。如无特殊必要,我们不建议使用该形式进行协同开发,多次修改配置会导致出错的概率增加。
- 本地环境首次启动时,除了修改Redis相关配置外,还需要配置
pamirs.distribution.session.allMetaRefresh=true,将本地新连接的Redis进行初始化。 - 在本地启动时,增加
-PenvProtected=false -PsaveEnvironments=false启动参数,以确保本地启动不会修改公共环境的配置,并且可以正常通过环境保护检测。 - 本地环境成功启动并正常开发功能后,需要发布到公共环境进行测试时,需要先修改公共环境中业务工程配置
pamirs.distribution.session.allMetaRefresh=true后,再启动业务工程。 - 启动一次业务工程后,将配置还原为
pamirs.distribution.session.allMetaRefresh=false。