ORM API
一、模型 Model
模型由元信息、字段、数据管理器和自定义函数构成。
模型分为元模型和业务模型。元数据是指描述应用程序运行所必需的数据、规则和逻辑的数据集;元模型是指用于描述内核元数据的一套模式集合;业务模型是指用于描述业务应用元数据的一套模式集合。
元模型分为模块域、模型域和函数域三个域。域的划分规则是根据元模型定义数据关联关系的离散性来判断,离散程度越小越聚集到一个域。
(一)模型的类型
1、抽象模型:
往往是提供公共能力和字段的模型,它本身不会直接用于构建协议和基础设施(如表结构等)。
@Model.Advanced(type = ModelTypeEnum.ABSTRACT)
@Model.model(TestCommonItem.MODEL_MODEL)
@Model(displayName = "测试抽象模型", summary = "测试抽象模型")
public class TestCommonItem extends IdModel {
private static final long serialVersionUID = 7927471701701984895L;
public static final String MODEL_MODEL = "test.TestCommonItem";
// 此处省略公用字段配置
}通过 @Model.Advanced(type = ModelTypeEnum.ABSTRACT) 注解,可将模型标记为抽象模型。这类模型能够构建可复用的公共抽象业务模型库,在业务场景中,若需进行数据存储,可在扩展模块中创建存储模型,直接继承抽象业务模型库中的抽象模型,快速复用其模型结构与字段配置,有效提升开发效率。
2、传输模型:
用于表现层和应用层之间的数据交互,本身不会存储,没有默认的数据管理器,只有数据构造器。
@Model.Advanced(type = ModelTypeEnum.TRANSIENT)
@Model.model(TestRemark.MODEL_MODEL)
@Model(displayName = "测试传输模型", summary = "测试传输模型")
public class TestRemark extends TransientModel {
private static final long serialVersionUID = 5587370859051459028L;
public static final String MODEL_MODEL = "test.TestRemark";
// 此处省略传输字段配置
}可通过两种方式将模型定义为传输模型:
- 采用
@Model.Advanced(type = ModelTypeEnum.TRANSIENT)注解进行标注; - 让模型继承
TransientModel类。这两种方式均可快速明确模型的传输用途,实现数据在不同组件或模块间的高效传递 。
3、存储模型:
存储模型用于定义数据表结构和数据的增删改查(数据管理器)功能,是直接与连接器进行交互的数据容器。
@Model.model(TestModel.MODEL_MODEL)
@Model(displayName = "测试模型",labelFields = {"name"})
public class TestModel extends IdModel {
public static final String MODEL_MODEL="test.TestModel";
@Field(displayName = "名称")
private String name;
}4、代理模型:
用于代理存储模型的数据管理器能力的同时,扩展出非存储数据信息的交互功能的模型。
@Model.Advanced(type = ModelTypeEnum.PROXY)
@Model.model(Context.MODEL_MODEL)
@Model(displayName = "测试代理模型", summary = "测试代理模型")
public class TestProxyModel extends IdModel {
public static final String MODEL_MODEL = "test.TestProxyModel";
// 此处省略传输字段配置
}使用@Model.Advanced(type = ModelTypeEnum.PROXY)注解标识代理模型。
(二)模型定义种类
模型定义就是模型描述,不同定义类型,代表计算描述模型的元数据的规则不同
- 静态模型定义:模型元数据不持久化、不进行模型定义的计算(默认值、主键、继承、关联关系)
- 静态计算模型定义:模型元数据不持久化但初始化时进行模型定义计算获得最终的模型定义
- 动态模型定义:模型元数据持久化且初始化时进行模型定义计算获得最终的模型定义
静态模型定义需要使用@Model.Static进行注解;静态计算模型定义使用@Model.Static(compute=true)进行注解;动态模型定义不注解@Model.Static注解。
(三)安装与更新
使用@Model.model来配置模型的不可变更编码。模型一旦安装,无法在对该模型编码值进行修改,之后的模型配置更新会依据该编码进行查找并更新;如果仍然修改该注解的配置值,则系统会将该模型识别为新模型,存储模型会创建新的数据库表,而原表将会rename为废弃表。
如果模型配置了@Base注解,表明在模型设计器中该模型配置不可变更;如果字段配置了@Base注解,表明在模型设计器中该字段配置不可变更。
(四)基础配置
1、模型基类
所有的模型都需要继承以下模型中的一种,来表明模型的类型,同时继承以下模型的默认数据管理器。
- 继承BaseModel,构建存储模型,默认无id属性。
- 继承BaseRelation,构建多对多关系模型,默认无id属性。
- 继承TransientModel,构建临时模型(传输模型),临时模型没有数据管理器,也没有id属性。
- 继承EnhanceModel,构建数据源为ElasticSearch的增强模型。
2、快捷继承
- 继承IdModel,构建主键为id的模型。继承IdModel的模型会数据管理器会增加queryById方法(根据id查询单条记录)
- 继承CodeModel,构建带有唯一编码code的主键为id的模型。可以使用@Model.Code注解配置编码生成规则。也可以直接重载CodeModel的generateCode方法或者自定义新增的前置扩展点自定义编码生成逻辑。继承CodeModel的模型会数据管理器会增加queryByCode方法(根据唯一编码查询单条记录)
- 继承VersionModel,构建带有乐观锁,唯一编码code且主键为id的模型。
- 继承IdRelation,构建主键为id的多对多关系模型。
3、模型继承关系图
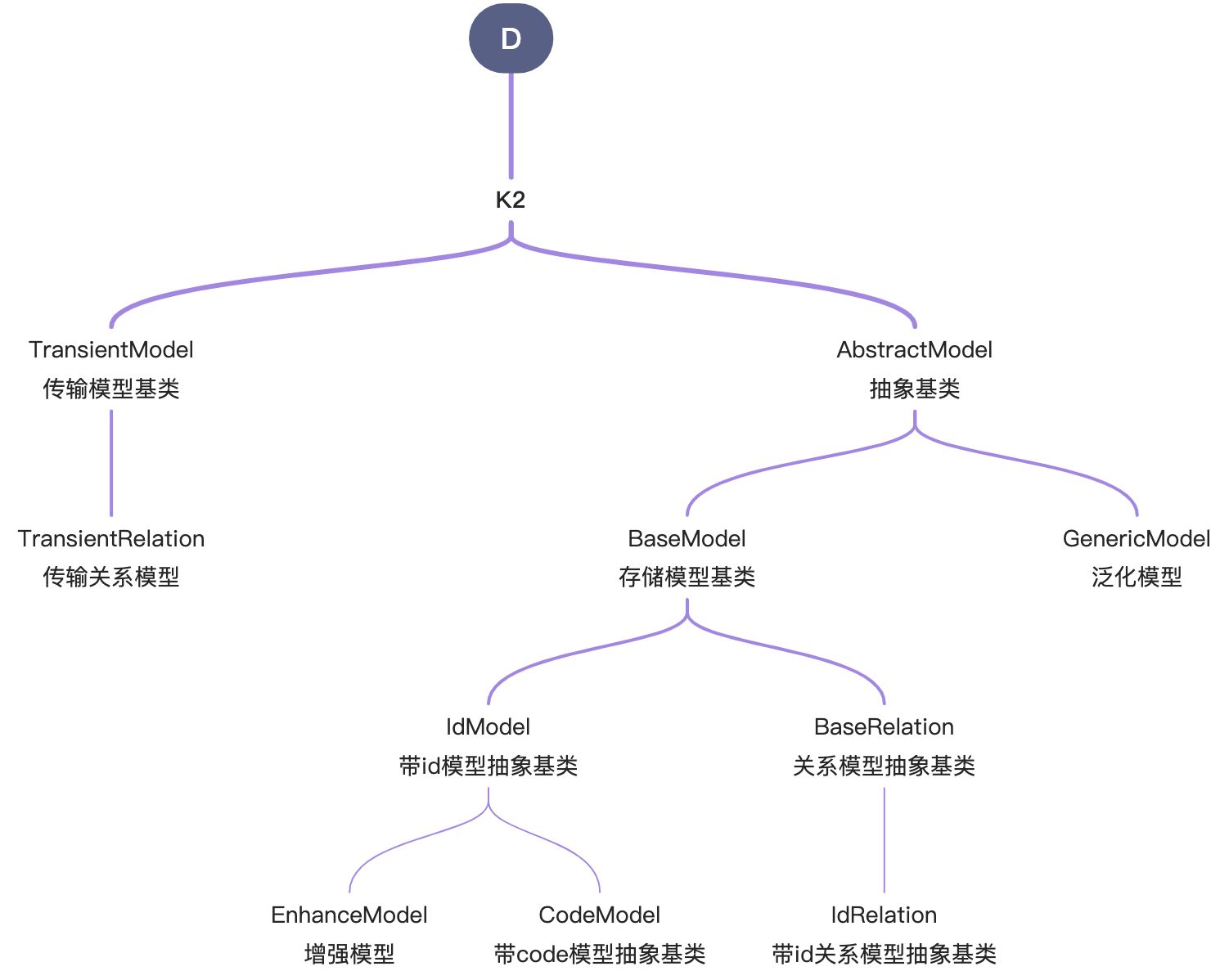
- AbstractModel抽象基类是包含createDate创建时间、writeDate更新时间、createUid创建用户ID、writeUid更新用户ID、aggs聚合结果和activePks批量主键列表等基础字段的抽象模型。
- TransientModel传输模型抽象基类是所有传输模型的基类,传输模型不存储,没有数据管理器。
- TransientRelation传输关系模型是所有传输关系模型的基类,传输关系模型不存储,用于承载多对多关系,没有数据管理器。
- BaseModel存储模型基类提供数据管理器功能,数据模型主键可以不是ID。
- IdModel带id模型抽象基类,在BaseModel数据管理器基础之上提供根据ID查询、更新、删除数据的功能。
- BaseRelation关系模型抽象基类用于承载多对多关系,是多对多关系的中间模型,数据模型主键可以不是ID。
- IdRelation带id模型抽象基类,在BaseModel数据管理器基础之上提供根据ID查询、更新、删除数据的功能。
- CodeModel带code模型抽象基类,提供按配置生成业务唯一编码功能,根据code查询、更新、删除数据的功能。
- EnhanceModel增强模型,提供全文检索能力。
4、注解配置 @Model
模型类必需使用@Model注解来标识当前类为模型类。
可以使用@Model.model、@Fun注解模型的模型编码(也表示命名空间),先取@Model.model注解值,若为空则取@Fun注解值,若皆为空则取全限定类名。
使用@Model.model注解配置模型编码,模型编码唯一标识一个模型。
警告
请勿使用Query和Mutation作为模型编码和技术名称的结尾。
@Model.model(TestModel.MODEL_MODEL)
@Model(displayName = "测试模型",labelFields = {"name"})
public class TestModel extends IdModel {
public static final String MODEL_MODEL="test.TestModel";
@Field(displayName = "名称")
private String name;
}@Model
├── displayName 显示名称
├── summary 描述摘要
├── labelFields 数据标题, 用于前端展示
├── label 数据标题格式, 默认为空
├── model 模型编码
│ └── value
├── Ds 逻辑数据源名
│ └── value
├── Advanced 更多配置
│ ├── name 技术名称,默认取model.model的点分割最后一位
│ ├── priority 排序
│ ├── chain 是否是链式模型
│ ├── table 逻辑数据表名
│ ├── remark 表备注,默认取简介summary
│ ├── index 索引/联合索引
│ ├── unique 唯一索引
│ ├── managed 可被管理,例如自动建表或更新表,默认为true
│ ├── ordering 数据排序
│ ├── type 模型类型,默认:STORE存储模型
│ ├── relationship 是否是描述多对多关系的模型
│ ├── supportClient 支持客户端 默认为true
│ ├── inherited 继承,配模型编码
│ ├── inheritedClass 继承类,配置模型所在类
│ ├── unInheritedFields 不从父类继承的字段
│ └── unInheritedFunctions 不从父类继承的函数
├── MultiTable
│ └── typeField 多表继承父模型中的类型字段编码
├── MultiTableInherited 子模型多表继承父模型
│ ├── type 多表继承父模型中的类型字段值
│ └── redundancy 冗余父模型除主键值外的数据
├── ChangeTableInherited 换表继承
├── Persistence 数据持久层配置,如不配置,则跟随模块配置,如配置,则取模型中的配置
│ ├── logicDelete 是否逻辑删除,默认为true
│ ├── logicDeleteColumn 逻辑删除列,默认“is_deleted”
│ ├── logicDeleteValue 逻辑删除后字段值,默认“REPLACE(unix_timestamp(NOW(6)),'.','')”
│ ├── logicNotDeleteValue 逻辑删除列默认值,默认“0”
│ ├── underCamel 下划线驼峰转化,默认为true
│ ├── capitalMode 表大写模式,默认为false
│ ├── charset 默认为 utf8mb4
│ └── collate 默认为 bin
├── Code 模型编码生成器,如果配置该属性,模型必须有code字段
│ ├── sequence 序列生成函数,可选值
- SEQ——自增流水号(不连续)
- ORDERLY——自增强有序流水号(连续)
- DATE_SEQ——日期+自增流水号(不连续)
- DATE_ORDERLY_SEQ——日期+强有序流水号(连续)
- DATE——日期
- UUID——随机32位字符串,包含数字和小写英文字母
│ ├── prefix 前缀
│ ├── suffix 后缀
│ ├── size 长度
│ ├── step 步长(包含流水号有效)
│ ├── initial 起始值(包含流水号有效)
│ ├── format 格式化(包含日期有效)
│ └── separator 分隔符
├── Static 静态模型配置
│ ├── module 模块
│ ├── moduleAbbr 模块缩略
│ └── onlyBasicTypeField 默认值为true
└── Fuse 低无一体融合模型
5、模型命名规范
| 模型属性 | 默认取值规范 | 命名规则规范 |
|---|---|---|
| name | 默认取model.model的点分割最后一位 | 1. 仅支持数字、字母 2. 必须以字母开头 3. 长度必须小于等于128个字符 |
| model | 默认使用全类名,取lname的值 开发人员定义规范示例: {项目名称}.{模块功能示意名称}. | 1. 仅支持数字、字母、点 2. 必须以字母开头 3. 不能以点结尾 4. 长度必须小于等于128个字符 |
| display_name | 空字符串 | 1. 长度必须小于等于128个字符 |
(五)模型元信息
模型的priority,当展示模型定义列表时,使用priority配置来对模型进行排序。
模型的ordering,使用ordering属性来配置该模型的数据列表的默认排序。
模型元信息继承形式:
- 不继承(N)
- 同编码以子模型为准(C)
- 同编码以父模型为准(P)
- 父子需保持一致,子模型可缺省(P=C)
注意:模型上配置的索引和唯一索引不会继承,所以需要在子模型重新定义。数据表的表名、表备注和表编码最终以父模型配置为准;扩展继承父子模型字段编码一致时,数据表字段定义以父模型配置为准。
| 名称 | 描述 | 抽象继承 | 同表继承 | 代理继承 | 多表继承 |
|---|---|---|---|---|---|
| 基本信息 | |||||
| displayName | 显示名称 | N | N | N | N |
| summary | 描述摘要 | N | N | N | N |
| label | 数据标题格式 | N | N | N | N |
| labelFields | 数据标题字段 | C | C | C | C |
| check | 模型校验方法 | N | N | N | N |
| rule | 模型校验表达式 | N | N | N | N |
| 模型编码 | |||||
| model | 模型编码 | N | N | N | N |
| 高级特性 | |||||
| name | 技术名称 | N | N | N | N |
| table | 逻辑数据表名 | N | P=C | P=C | N |
| type | 模型类型 | N | N | N | N |
| chain | 是否是链式模型 | N | N | N | N |
| index | 索引 | N | N | N | N |
| unique | 唯一索引 | N | N | N | N |
| managed | 需要数据管理器 | N | N | N | N |
| priority | 优先级,默认100 | N | N | N | N |
| ordering | 模型查询数据排序 | N | N | N | N |
| relationship | 是否是多对多关系模型 | N | N | N | N |
| inherited | 多重继承 | N | N | N | N |
| unInheritedFields | 不从父类继承的字段 | N | N | N | N |
| unInheritedFunctions | 不从父类继承的函数 | N | N | N | N |
| 高级特性-数据源 | |||||
| dsKey | 数据源 | N | P=C | P=C | N |
| 高级特性-持久化 | |||||
| logicDelete | 是否逻辑删除 | P | P | P | N |
| logicDeleteColumn | 逻辑删除字段 | P | P | P | N |
| logicDeleteValue | 逻辑删除状态值 | P | P | P | N |
| logicNotDeleteValue | 非逻辑删除状态值 | P | P | P | N |
| underCamel | 字段是否驼峰下划线映射 | P | P | P | N |
| capitalMode | 字段是否大小写映射 | P | P | P | N |
| 高级特性-序列生成配置 | |||||
| sequence | 配置编码 | C | C | C | N |
| prefix | 前缀 | C | C | C | N |
| suffix | 后缀 | C | C | C | N |
| separator | 分隔符 | C | C | C | N |
| size | 序列长度 | C | C | C | N |
| step | 序列步长 | C | C | C | N |
| initial | 初始值 | C | C | C | N |
| format | 序列格式化 | C | C | C | N |
| 高级特性-关联关系(或逻辑外键) | |||||
| unique | 外键值是否唯一 | C | C | C | N |
| foreignKey | 外键名称 | C | C | C | N |
| relationFields | 关系字段列表 | C | C | C | N |
| references | 关联模型 | C | C | C | N |
| referenceFields | 关联字段列表 | C | C | C | N |
| limit | 关系数量限制 | C | C | C | N |
| pageSize | 查询每页个数 | C | C | C | N |
| domainSize | 模型筛选可选项每页个数 | C | C | C | N |
| domain | 模型筛选,前端可选项 | C | C | C | N |
| onUpdate | 更新关联操作 | C | C | C | N |
| onDelete | 删除关联操作 | C | C | C | N |
| 静态配置 | |||||
| Static | 静态元数据模型 | N | N | N | N |
字段定义继承形式
| 名称 | 描述 | 抽象继承 | 同表继承 | 代理继承 | 多表继承 |
|---|---|---|---|---|---|
| 字段定义 | 字段定义 | C | C | C | C |
(六)模型约束
1、Sql 约束
每个模型都可以配置自身的主键列表,也可以不配置主键。主键值不可缺省,可以索引到模型所对应数据表中唯一的一条记录。
接下来,我们将进一步介绍几个与数据库相关的属性。
- @Field(index),请求 Oinone 在该列上创建数据库索引。
- @Field(unique),请求 Oinone 在该列上创建数据库唯一索引。
- @PrimaryKey,请求 Oinone 在该列上创建数据库主健约束。
- @Field.Advanced(columnDefinition),请求 Oinone 在该列上创建数据库列定义。
@Field(displayName = "名称")
@Field.Advanced(columnDefinition = "varchar(12) NOT NULL ")
private String name;2、校验约束 Validation
模型或字段可以配置校验函数以及规则对该模型的数据进行校验,存储数据时,校验数据是否合法合规。
SQL 约束是确保数据一致性的有效方法。然而,我们的应用程序并不想跟具体的数据库进行强绑定,甚至有更复杂的检查,这就需要用到 JAVA 代码。在这种情况下,我们就需要校验约束。
校验约束被定义为一个使用 @Validation 注解的模型与字段,并在一个记录集上调用。当这些字段中的任何一个被修改时,约束会自动进行评估。如果约束规则不满足,该方法应抛出一个异常:
@Validation(ruleWithTips = {
@Validation.Rule(value = "!IS_NULL(age)", error = "年龄为必填项"),
@Validation.Rule(value = "age >=0 && age <= 200", error = "年龄只能在0-200之间"),
})
@Field(displayName = "年龄")
private Integer age;- 多规则配置:通过
ruleWithTips数组可声明多条校验规则,每条规则由@Validation.Rule定义,包含value(校验表达式)和error(错误提示)两个参数。 - 内置函数支持:支持
IS_BLANK(判断文本是否为空)、LEN(获取文本长度)等内置函数,完整函数列表与使用方法详见内置函数
若需要开展更为复杂的检查工作,可在模型与字段定义时使用 @Validation(check="X"),其中 X 指代给定模型的一个函数。
……
@Model.model(TestConstraintsModel.MODEL_MODEL)
@Model(displayName = "约束测试模型")
@Validation(check = "checkData")
public class TestConstraintsModel extends IdModel {
……
@Function
public Boolean checkData(TestConstraintsModel data) {
String name = data.getName();
boolean success = true;
if (StringUtils.isBlank(name)) {
PamirsSession.getMessageHub()
.msg(Message.init()
.setLevel(InformationLevelEnum.ERROR)
.setField(LambdaUtil.fetchFieldName(TestConstraintsModel::getName))
.setMessage("名称为必填项"));
success = false;
}
if (name.length() > 4) {
PamirsSession.getMessageHub()
.msg(Message.init()
.setLevel(InformationLevelEnum.ERROR)
.setField(LambdaUtil.fetchFieldName(TestConstraintsModel::getName))
.setMessage("名称过长,不能超过4位"));
success = false;
}
return success;
}
}提示
- 在 Oinone 中,可通过
@Validation注解对 Action 操作添加校验约束。 - 该校验机制仅在前端发起请求时触发生效,以确保数据合法性;而通过 Java 代码直接调用时,此校验逻辑 不会自动执行,避免因重复校验带来额外性能开销,帮助开发者灵活控制校验场景,平衡系统性能与数据验证需求。
提示
通过网关协议 API 文档的 requestStrategy 策略,可灵活激活 Validation 校验能力。支持设置函数仅校验不提交,自由选择检查完成后返回或失败即返回,还能定制消息返回规则,仅展示失败信息 。
(七)数据管理
在 Oinone 中,数据管理器和数据构造器是系统为模型自动配备的核心功能组件,为模型提供了强大的内在数据管理能力。
数据管理器:针对存储模型设计,在编程过程中,开发者可直接调用其提供的 Function,快速实现数据查询、更新、删除等常见操作,显著提升数据处理效率。
数据构造器:主要用于模型初始化场景,负责计算字段默认值,同时也在页面交互环节发挥重要作用,确保数据在前端与后端之间的正确传递和展示。
1、数据管理函数
以 test.ExtendIdModel 模型(继承自 IdModel)为例,查询函数为数据管理器函数( data_manager=1 ),其中bean_name:即函数定义所在 Java 类的 bean 名称。另外 type 和 open_level 采用按位与方式表示功能含义:
type取值:CREATE(1L)新增、DELETE(2L)删除、UPDATE(4L)更新、QUERY(8L)查询open_level取值:LOCAL(2)本地调用、REMOTE(4)远程调用、API(8)开放接口
数据管理器中,默认读函数列表:
mysql> select method,fun,open_level,bean_name from base_function where namespace ='test.ExtendIdModel'and data_manager=1 and type&8=8;
+--------------------------------+--------------------------------+------------+-----------------------+
| method | fun | open_level | bean_name |
+--------------------------------+--------------------------------+------------+-----------------------+
| construct | construct | 14 | constructManager |
| count | count | 14 | defaultReadApi |
| count | countByWrapper | 14 | defaultReadApi |
| queryOne | queryByEntity | 14 | defaultReadApi |
| queryById | queryById | 6 | defaultIdDataManager |
| queryByPk | queryByPk | 14 | defaultReadApi |
| queryOneByWrapper | queryByWrapper | 14 | defaultReadApi |
| queryFilters | queryFilters | 2 | defaultReadFiltersApi |
| queryListByEntity | queryListByEntity | 14 | defaultReadApi |
| queryListByEntityWithBatchSize | queryListByEntityWithBatchSize | 6 | defaultReadApi |
| queryListByEntity | queryListByPage | 6 | defaultReadApi |
| queryListByWrapper | queryListByPageAndWrapper | 6 | defaultReadApi |
| queryListByWrapper | queryListByWrapper | 14 | defaultReadApi |
| queryPage | queryPage | 14 | defaultReadApi |
| relationQueryPage | relationQueryPage | 14 | defaultReadApi |
+--------------------------------+--------------------------------+------------+-----------------------+
15 rows in set (0.00 sec)数据管理器中,默认写函数列表:
mysql> select method,fun,open_level,bean_name from base_function where namespace ='test.ExtendIdModel'and data_manager=1 and type&8!=8;
+---------------------------------------+---------------------------------------+------------+--------------------------+
| method | fun | open_level | bean_name |
+---------------------------------------+---------------------------------------+------------+--------------------------+
| createWithField | create | 14 | defaultWriteWithFieldApi |
| createBatch | createBatch | 6 | defaultWriteApi |
| createBatchWithSize | createBatchWithSize | 6 | defaultWriteApi |
| createOne | createOne | 6 | defaultWriteApi |
| createOrUpdate | createOrUpdate | 6 | defaultWriteApi |
| createOrUpdateBatch | createOrUpdateBatch | 6 | defaultWriteApi |
| createOrUpdateBatchWithResult | createOrUpdateBatchWithResult | 6 | defaultWriteApi |
| createOrUpdateBatchWithSize | createOrUpdateBatchWithSize | 6 | defaultWriteApi |
| createOrUpdateBatchWithSizeWithResult | createOrUpdateBatchWithSizeWithResult | 6 | defaultWriteApi |
| createOrUpdateWithField | createOrUpdateWithField | 6 | defaultWriteWithFieldApi |
| createOrUpdateWithFieldBatch | createOrUpdateWithFieldBatch | 6 | defaultWriteWithFieldApi |
| createOrUpdateWithResult | createOrUpdateWithResult | 6 | defaultWriteApi |
| createWithFieldBatch | createWithFieldBatch | 6 | defaultWriteWithFieldApi |
| deleteWithField | delete | 6 | defaultWriteWithFieldApi |
| deleteByEntity | deleteByEntity | 6 | defaultWriteApi |
| deleteById | deleteById | 6 | defaultIdDataManager |
| deleteByPk | deleteByPk | 6 | defaultWriteApi |
| deleteByPks | deleteByPks | 6 | defaultWriteApi |
| deleteByUniqueField | deleteByUniqueField | 6 | defaultWriteApi |
| deleteByUniques | deleteByUniques | 6 | defaultWriteApi |
| deleteByWrapper | deleteByWrapper | 6 | defaultWriteApi |
| deleteWithFieldBatch | deleteWithFieldBatch | 14 | defaultWriteWithFieldApi |
| updateWithField | update | 14 | defaultWriteWithFieldApi |
| updateBatch | updateBatch | 6 | defaultWriteApi |
| updateBatchWithSize | updateBatchWithSize | 6 | defaultWriteApi |
| updateByEntity | updateByEntity | 6 | defaultWriteApi |
| updateById | updateById | 6 | defaultIdDataManager |
| updateByPk | updateByPk | 6 | defaultWriteApi |
| updateByUniqueField | updateByUniqueField | 6 | defaultWriteApi |
| updateByWrapper | updateByWrapper | 6 | defaultWriteApi |
| updateOneWithRelations | updateOneWithRelations | 14 | defaultWriteApi |
| updateWithFieldBatch | updateWithFieldBatch | 14 | defaultWriteWithFieldApi |
+---------------------------------------+---------------------------------------+------------+--------------------------+
32 rows in set (0.00 sec)提示
在查看模型函数表时,默认数据管理函数集中定义于 constructManager、defaultReadApi、defaultWriteApi、defaultWriteWithFieldApi、defaultIdDataManager 等 Java 类中,我们可以试着追溯其来源父模型与实现逻辑。比如defaultIdDataManager定义的是 IdModel ,那么我们就清楚哪些函数是继承至 IdModel 。
2、数据管理器
只有存储模型才有数据管理器。如果@Model.Advanced注解设置了dataManager属性为false,则表示在UI层不开放默认数据管理器。开放级别为API则表示UI层可以通过HTTP请求利用Pamirs标准网关协议进行数据交互。
继承 IdModel
模型继承 IdModel 后,主键自动设为 id,并继承 queryById、updateById 和 deleteById 函数,开放级别均为 Remote,分别用于按 ID 查询、更新和删除单条记录。
继承 CodeModel
继承 CodeModel 会一并继承 IdModel 的数据管理器,code 作为唯一索引字段,新增数据时按规则自动赋值,同时继承 queryByCode、updateByCode 和 deleteByCode 函数,同样为 Remote 开放级别。
无主键或唯一索引模型
无主键或唯一索引的模型,UI 层不开放默认数据写管理器。
3、数据构造器
在 Oinone 中,模型数据构造器construct用于为前端新开页面提供默认数据。所有模型均内置此构造器,默认返回字段配置的默认值(枚举类型默认值为枚举名称)。如需自定义逻辑,可在子类中重载construct方法。
construct函数开放级别为API,属于QUERY查询类型。系统会自动将模型中名为construct的函数设置为此固定属性。默认值可通过@Field注解的defaultValue属性配置。
二、字段 Field
模型字段用于定义实体的特征属性,通过 Model 类的 model 与 Field 类的 model 建立关联关系,ModelField继承于抽象类 Relation 构建。
字段定义采用 @Field 注解。若未显式指定字段类型,系统将自动识别 Java 代码中的字段声明类型作为业务类型。为确保前端展示规范,建议通过 displayName 属性设置字段展示名称;同时,可利用 defaultValue 属性配置字段默认值。
(一)字段的类型
类型系统由基本类型、复合(组件)类型、引用类型和关系类型四种类型系统构成。通过类型系统描述应用程序、数据库和前端视觉视图如何进行交互,数据及数据间关系如何处理的协议。
1、基础类型
| Ttype枚举 | 注解 | 描述 |
|---|---|---|
| TtypeEnum.BINARY | Field.Binary | 二进制 |
| TtypeEnum.INTEGER | Field.Integer | 整数 |
| TtypeEnum.FLOAT | Field.Float | 浮点数 |
| TtypeEnum.BOOLEAN | Field.Boolean | 布尔 |
| TtypeEnum.STRING | Field.String | 文本 |
| TtypeEnum.TEXT | Field.Text | 多行文本 |
| TtypeEnum.HTML | Field.Html | 富文本 |
| TtypeEnum.ENUM | Field.Enum | 枚举 |
| TtypeEnum.DATETIME | Field.Date | 日期时间 |
| TtypeEnum.YEAR | Field.Date(type = DateTypeEnum.YEAR, format = DateFormatEnum.YEAR) | 年份 |
| TtypeEnum.DATE | Field.Date(type = DateTypeEnum.DATE, format = DateFormatEnum.DATE) | 日期 |
| TtypeEnum.TIME | Field.Date(type = DateTypeEnum.TIME, format = DateFormatEnum.TIME) | 时间 |
二进制类型(BINARY)
- Java 类型:Byte、Byte[]
- 数据库类型:TINYINT、BLOB
- 规则:此为二进制类型,同时前端交互默认不支持。不建议使用
@Field(displayName = "byteField")
private Byte byteField;整数类型(INTEGER)
- Java 类型:Short、Integer、Long、BigInteger
- 数据库类型:smallint、int、bigint、decimal(size,0)
- 规则:
- 数据库规则:默认用 int;若 size 小于 6,用 smallint;size 超 6 用 int;size 超 10 位数字(含符号位),用长整数 bigint;size 超 19 位数字(含符号位),用大数 decimal。若未配置 size,按 Java 类型推测。
- 前端交互规则:整数用 Number 类型,长整数和大整数前后端协议用字符串类型。
@Field(displayName = "integerField")
private Integer integerField;举例

浮点类型(FLOAT)
- Java 类型:Float、Double、BigDecimal
- 数据库类型:float(M,D)、double(M,D)、decimal(M,D)
- 规则:
- 数据库规则:默认用单精度浮点数 float;size 超 7 位数字(即大于等于 8),用双精度浮点数 double;size 超 15 位数字(即大于等于 16),用大数 decimal。若未配置 size,按 Java 类型推测。
- 前端交互规则:单精度和双精度浮点数用 Number 类型(因都用 IEEE754 协议 64 位存储),大数前后端协议用字符串类型。
@Field(displayName = "floatField")
private BigDecimal floatField;举例

布尔类型(BOOLEAN)
- Java 类型:Boolean
- 数据库类型:tinyint(1)
- 规则:布尔类型,值为 1、true(真)或 0、false(假)。
@Field(displayName = "booleanField")
private Boolean booleanField;举例

枚举类型(ENUM)
- Java 类型:Enum
- 数据库类型:与数据字典指定基本类型一致
- 规则:
- 前端交互规则:可选项从 ModelField 的 options 字段获取,该字段值是字段指定数据字典子集的 JSON 序列化字符串。前后端传递可选项的 name,数据库存储用可选项的 value。若 multi 属性为 true,用多选控件;multi 属性为 false,用单元控件。
@Field.Enum
@Field(displayName = "testEnum")
private TestEnum testEnum;
@Field.Enum
@Field(displayName = "testEnums",multi = true)
private List<TestEnum> testEnums;
//当以枚举项值类型声明字段类型时,字段类型与枚举值类型必须严格保持一致。
@Field.Enum(dictionary=TestEnum.dictionary)
@Field(displayName = "testDictionaries",multi = true)
private List<String> testDictionaries;举例

注意
当以枚举项值类型声明字段类型时,字段类型与枚举值类型必须严格保持一致。
字符串类型(STRING)
- Java 类型:String
- 数据库类型:varchar(size)
- 规则:字符串,size 是长度限制默认值参考,前端可在 view 中覆盖该配置。
@Field.String(size = 128,min = "3",max = "128")
@Field(displayName = "stringField2")
private String stringField2;
@Field(displayName = "stringField")
private String stringField;举例

多行文本类型(TEXT)
- Java 类型:String
- 数据库类型:text
- 规则:多行文本,编辑态组件是多行文本框,长度限制为配置项 min 值 与 max 值 。
@Field.Text(min = "3",max = "512")
@Field(displayName = "textField")
private String textField;举例

富文本类型(HTML)
- Java 类型:String
- 数据库类型:text
- 规则:使用富文本编辑器。
@Field.Html
@Field(displayName = "htmlField")
private String htmlField;举例

日期时间类型(DATETIME)
- Java 类型:java.util.Date、java.sql.Timestamp
- 数据库类型:datetime(fraction)、timestamp(fraction)
- 规则:
- 数据库规则:是日期和时间的组合,时间格式为 YYYY - MM - DD HH:MM:SS [.fraction],默认精确到秒,可带小数,最多 6 位,即精确到 microseconds (6 digits) precision。可通过设置 fraction 设置精确小数位数,最终存储在字段的 decimal 属性上。
- 前端交互规则:前端默认用日期时间控件,按日期时间类型格式化格式 format 格式化日期时间。
@Field(displayName = "dateTimeField")
private Date dateTimeField;举例

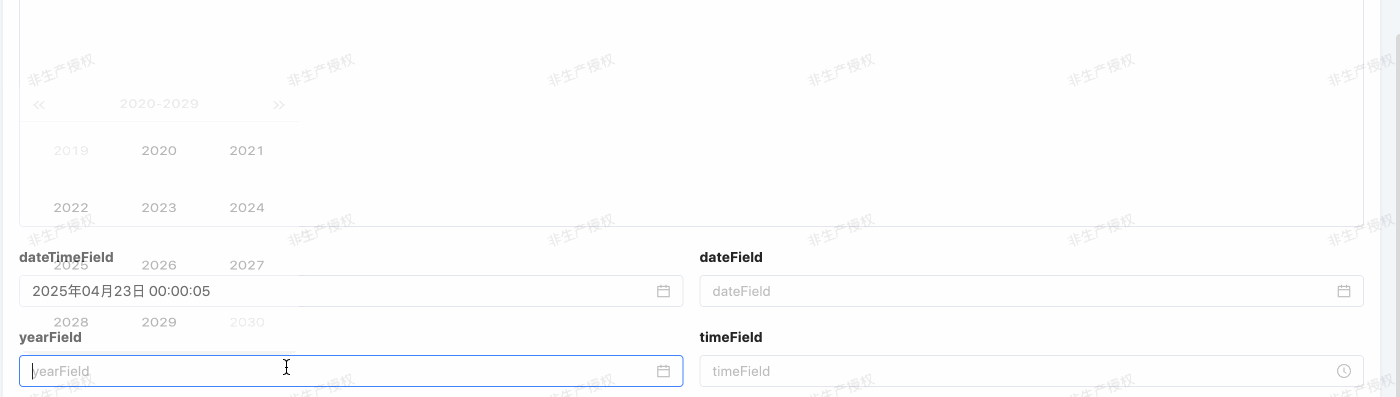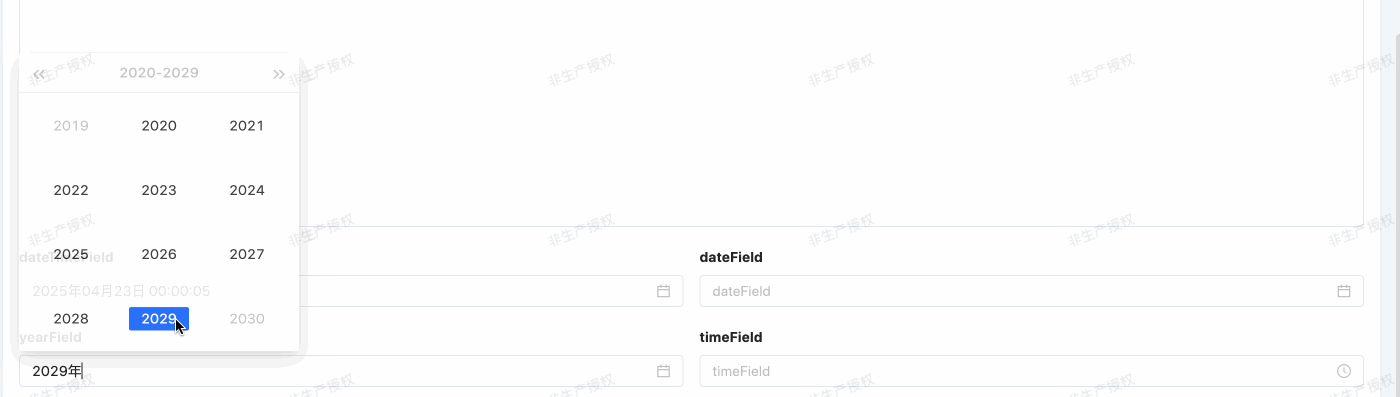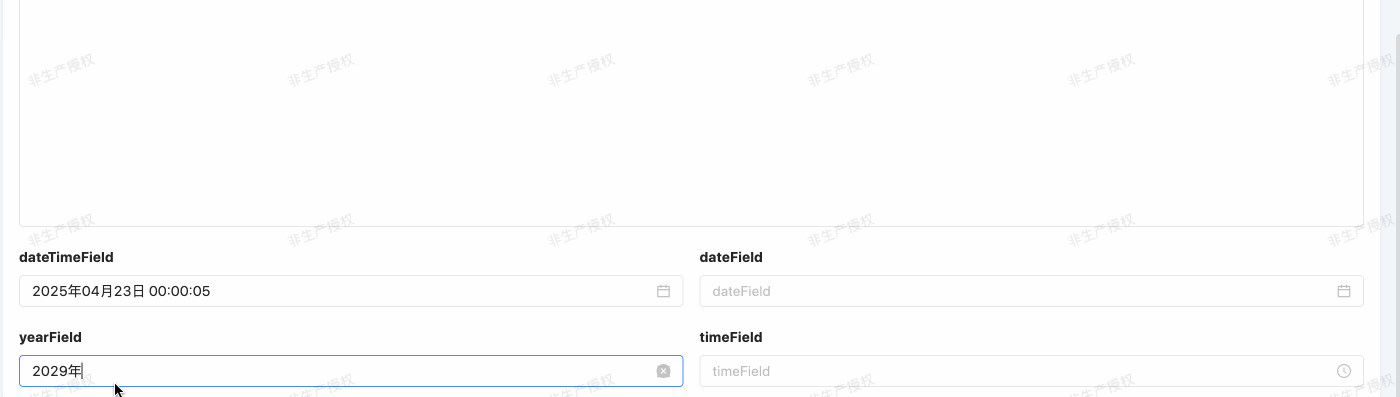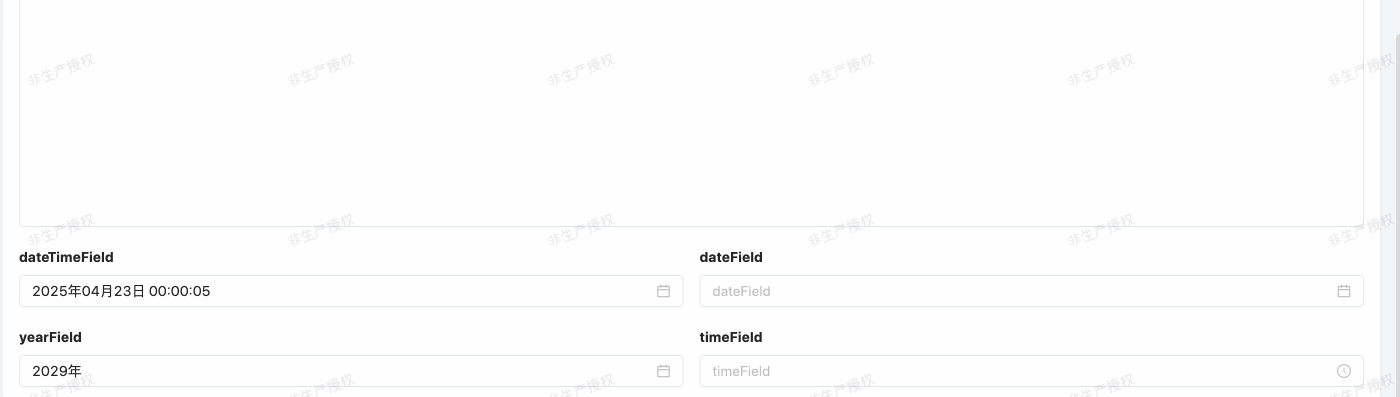
年份类型(YEAR)
- Java 类型:java.util.Date
- 数据库类型:year
- 规则:
- 数据库规则:默认以 “YYYY” 格式表示日期值。
- 前端交互规则:前端默认用年份控件,按日期类型格式化格式 format 格式化日期。
@Field.Date(type = DateTypeEnum.YEAR,format = DateFormatEnum.YEAR)
@Field(displayName = "yearField")
private Date yearField;举例
日期类型(DATE)
- Java 类型:java.util.Date、java.sql.Date
- 数据库类型:date
- 规则:
- 数据库规则:默认以 “YYYY - MM - DD” 格式表示日期值。
- 前端交互规则:前端默认用日期控件,按日期类型格式化格式 format 格式化日期。
@Field.Date(type = DateTypeEnum.DATE,format = DateFormatEnum.DATE)
@Field(displayName = "dateField")
private Date dateField;举例
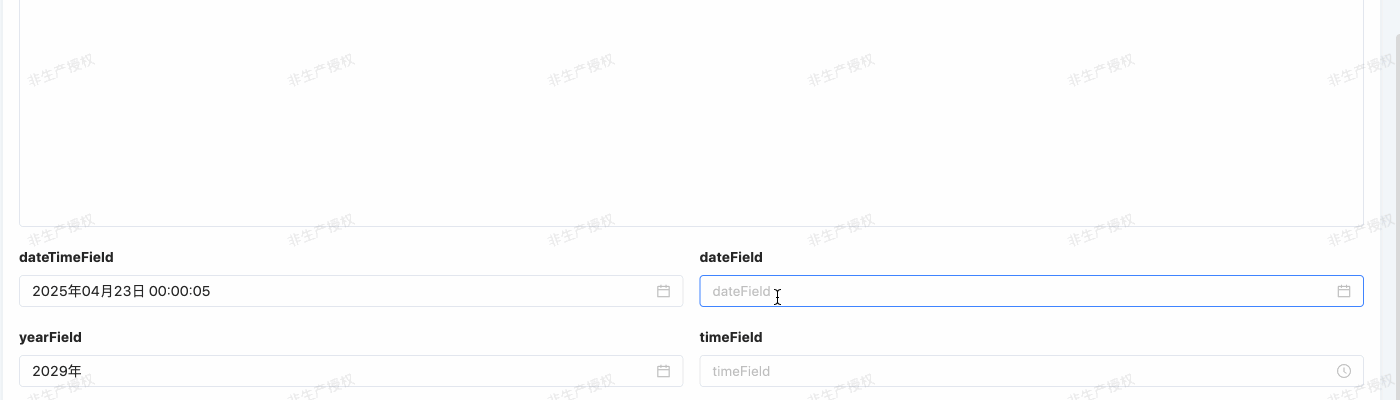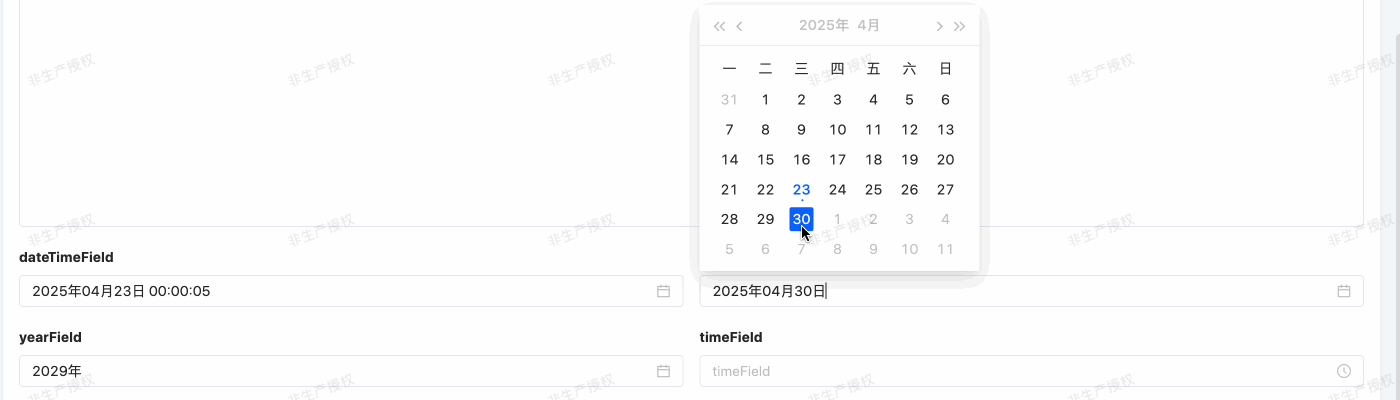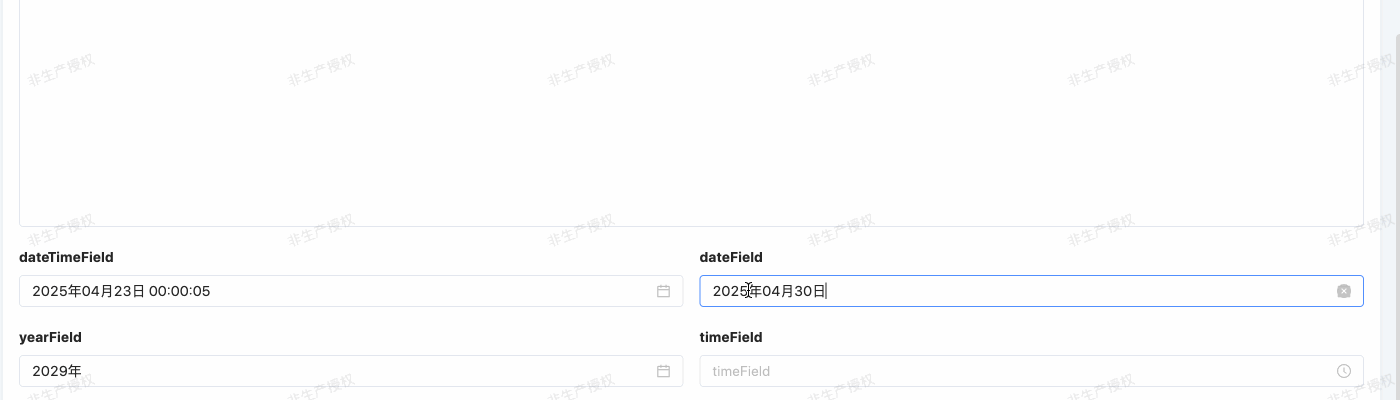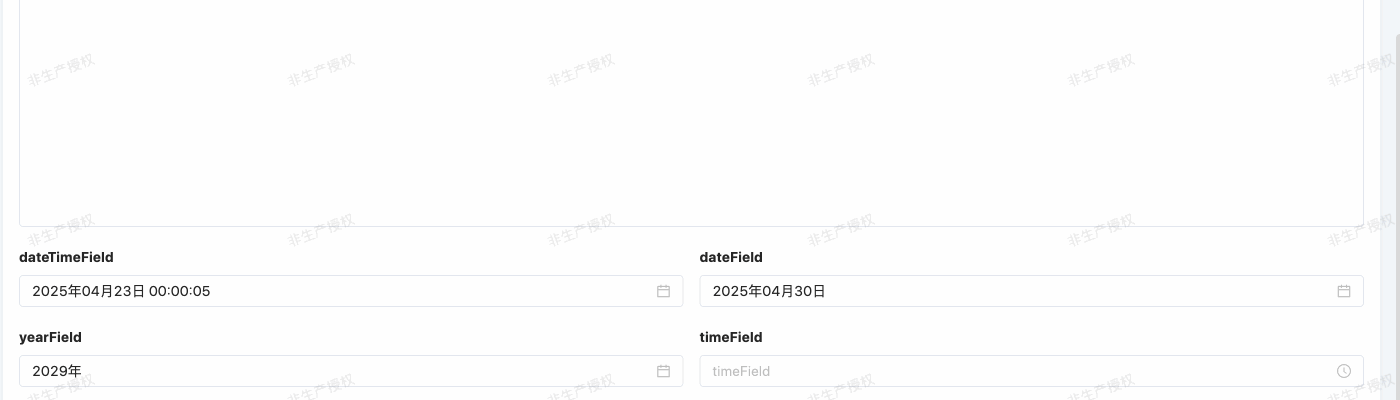
时间类型(TIME)
- Java 类型:java.util.Date、java.sql.Time
- 数据库类型:time(fraction)
- 规则:
- 数据库规则:默认以 “HH:MM:SS” 格式表示时间值。
- 前端交互规则:前端默认用时间控件,按日期类型格式化格式 format 格式化日期。
@Field.Date(type = DateTypeEnum.TIME,format = DateFormatEnum.TIME)
@Field(displayName = "timeField")
private Date timeField;举例

2、复合类型
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| MAP | Map | String | 键值对,序列化方式 Field.serialize.JSON |
| MONEY | BigDecimal | decimal(M,D) | 金额,前端使用金额控件,默认标度与精度为:数字最大位数 65,小数位数6 |
金额 MONEY
@Field.Money
@Field(displayName = "testMoney")
private BigDecimal testMoney;键值对 MAP
@Field(displayName = "testMapField")
private Map<String,Object> testMapField;举例

3、引用类型 RELATED
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| RELATED | 基本类型或关系类型 | 不存储或varchar、text | 引用字段 【数据库规则】:点表达式最后一级对应的字段类型;数据库字段值默认为Java字段的序列化值,默认使用JSON序列化 【前端交互规则】:点表达式最后一级对应的字段控件类型 |
@Field(displayName = "stringField")
private String stringField;
@Field.many2one
@Field(displayName = "用户",required = true)
@Field.Relation(relationFields = {"userId"},referenceFields = {"id"})
private PamirsUser user;
@Field.Related("stringField")
@Field(displayName = "引用字段stringField")
private String relatedStringField;
@Field.Related({"user","name"})
@Field(displayName = "引用创建者名称")
private String userName;举例

4、关系类型
是对模型间关联方式的描述,涵盖关联关系类型、关联关系双边的模型以及关联关系的读写操作。业务类型 ttype 为 O2O、O2M、M2O 或 M2M 的字段。
| 业务类型 | Java类型 | 数据库类型 | 规则说明 |
|---|---|---|---|
| O2O | 模型/DataMap | 不存储或varchar、text | 一对一关系 |
| M2O | 模型/DataMap | 不存储或varchar、text | 多对一关系 |
| O2M | List<模型/DataMap> | 不存储或varchar、text | 一对多关系 |
| M2M | List<模型/DataMap> | 不存储或varchar、text | 多对多关系 |
若需存储多值字段或关系字段,默认采用 JSON 格式进行序列化。多值字段的数据库字段类型默认为 varchar (1024),而关系字段的数据库字段类型则默认为 text。
关联关系用于描述模型间的关联方式:
- 多对一关系,主要用于明确从属关系
- 一对多关系,主要用于明确从属关系
- 多对多关系,主要用于弱依赖关系的处理,提供中间模型进行关联关系的操作
- 一对一关系,主要用于多表继承和行内合并数据
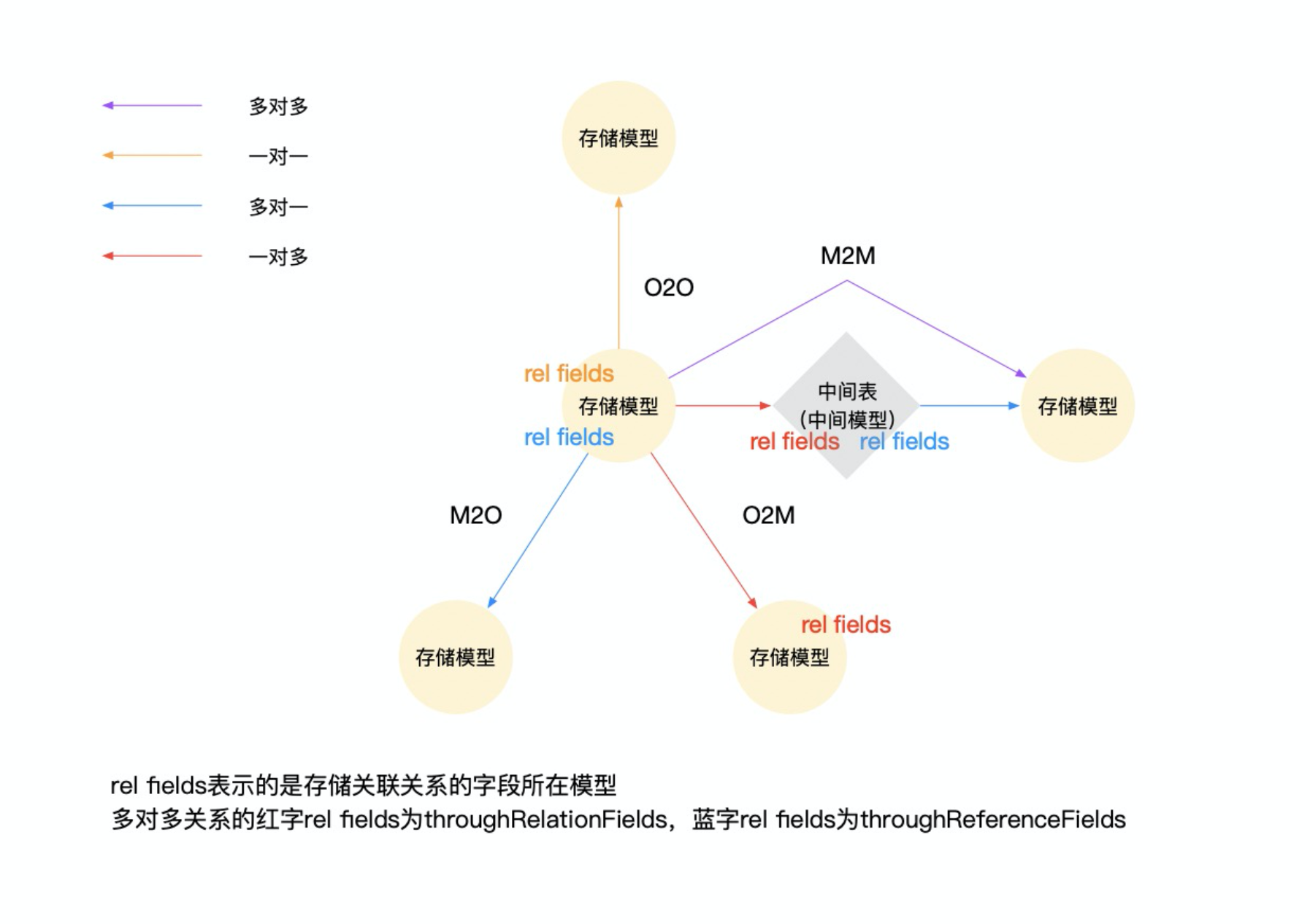
关联关系比较重要的名词解释如下:
- 关联模型:用
references表示,指自身模型所关联的模型。 - 关联字段:用
referenceFields表示,是关联模型的字段,用于明确关联模型的哪些字段与自身模型的哪些字段建立关系。 - 关系模型:即 自身模型。
- 关系字段:用
relationFields表示,是自身模型的字段,用于明确自身模型的哪些字段与关联模型的哪些字段建立关系。 - 中间模型:用
through表示,仅多对多关系存在中间模型,且模型的relationship=true。
多对一关系(many2one)
在字段上添加 @Field 注解后,若字段类型为模型,系统会推断该字段的 Ttype 为 many2one,并依据当前模型主键生成关联关系。例如,当前模型为 TestModel,关联模型为 TestRelationModel,主键为 id,则会在 TestModel 模型中生成 testRelationModelId 字段来保存关联关系。
@Field.Relation注解的relationFields属性:用于配置左端模型的属性作为关联字段,默认值为当前字段名称加上右端模型的主键属性。@Field.Relation注解的referenceFields属性:用于配置右端模型的属性作为关联字段,默认值为主键集合。
@Field.many2one
@Field(displayName = "多对一测试字段")
// 等同于配置 @Field.Relation(relationFields = {"rightModelId"},referenceFields = {"id"})
private TestRelationModel rightModel;该示例中,TestModel对应的表会默认生成right_model_id字段 。
一对多关系(one2many)
在字段上添加 @Field 注解后,若字段类型为 List<T>,系统会推断该字段的 Ttype 为 one2many,并依据当前模型主键生成关联关系。例如,当前模型为 TestModel,关联模型为 TestRelationModel,主键为 id,则会在 TestRelationModel 模型中生成 testModelId 字段来保存关联关系。
@Field.one2many注解:可用于为该字段配置查询和提交策略等属性。@Field.Relation注解的relationFields属性:用于配置左端模型的属性作为关联字段,默认值为主键集合。@Field.Relation注解的referenceFields属性:用于配置右端模型的属性作为关联字段,默认值为左端模型的简单模型编码加主键属性。
@Field.one2many
@Field(displayName = "一对多测试字段")
// 等同于配置 @Field.Relation(relationFields = {"id"},referenceFields = {"testModelId"})
private List<TestRelationModel> rightModels;在此示例中,系统会在 TestRelationModel 对应的表中默认生成一个名为 test_model_id 的字段,用于建立与 TestModel 的关联关系。
多对多关系(many2many)
在字段上除了添加 @Field 注解,还需添加 @Field.many2many 注解来标识该字段为多对多类型。多对多关系需要配置中间模型,可通过 @Field.many2many 注解的 through 属性(值为中间模型编码,若没有中间模型的 Class,系统会根据关联关系字段配置自动生成中间模型)或 throughClass 属性(值为中间模型 Class)来确定中间模型,且这两个属性有且仅能配置一个。
@Field.many2many注解的relationFields属性:用于配置中间模型与左端模型关联的关系字段。若未配置,则使用关联关系字段配置的关系字段(@Field.Relation注解的relationFields配置值)作为默认值。@Field.many2many注解的referenceFields属性:用于配置中间模型与右端模型关联的关系字段。若未配置,则使用关联关系字段配置的关联字段(@Field.Relation注解的referenceFields配置值)作为默认值。 若没有中间模型的Class且左右两端模型都配置了关联关系字段,系统会采用先加载的模型的关联关系字段配置来生成中间模型。使用模型作为中间模型时,建议使用BaseRelation基类构造中间模型。
@Field.many2many
// 等同与把 @Field.many2many 换成下面注释掉的配置
// @Field.many2many(through = "TestModelRelTestRelationModel",relationFields = {"testModelId"},referenceFields = {"testRelationModelId"})
// @Field.Relation(relationFields = {"id"},referenceFields = {"id"})
@Field(displayName = "多对多测试字段")
private List<TestRelationModel> rightModelM2Ms;另一种配置:
@Model.model(TestModelRelTestRelationModel.MODEL_MODEL)
@Model(displayName = "测试中间表")
public class TestModelRelTestRelationModel extends BaseRelation {
public static final String MODEL_MODEL="test.TestModelRelTestRelationModel";
@Field(displayName = "testModelId")
private Long testModelId;
@Field(displayName = "TestRelationModelId")
private Long testRelationModelId;
}@Field.many2many(throughClass = TestModelRelTestRelationModel.class,relationFields = {"testModelId"},referenceFields = {"testRelationModelId"})
@Field.Relation(relationFields = {"id"},referenceFields = {"id"})
@Field(displayName = "多对多测试字段")
private List<TestRelationModel> rightModelM2Ms;在此示例中,在TestModel的Ds所指向的数据库中,会自动生成一张名为test_model_rel_test_relation_model的关联表。该表中,test_model_id字段与TestModel表的id字段关联,test_relation_model_id字段则与TestRelationModel表的id字段关联,用于建立两张表之间的关系。
关系字段的一些特殊场景
提示
当关联关系字段并非一一对应,且存在常量的情况,示例代码中 #1# 代表 type 为 1 ,可通过增加 domain 描述来实现特定过滤逻辑。在用户进行页面选择操作时,系统会依据此规则自动筛选出 type 为 1 的 TestRelationModel 数据记录。
@Field(displayName = "多对多")
@Field.many2many(
through = "TestModelRelTestRelationModel",
relationFields = {"testModelId"},
referenceFields = {"testRelationModelId","type"}
)
@Field.Relation(relationFields = {"id"}, referenceFields = {"id", "#1#"}, domain = " type == 1")
private List<TestRelationModel> petTalents;在上述代码中,通过 @Field.many2many 注解配置多对多关系的中间模型及关联字段,同时利用 @Field.Relation 注解的 domain 属性指定过滤条件,确保仅展示符合条件的数据。
5、类型默认推断
M代表精度,即有效长度(总位数), D代表标度,即小数点后的位数,fraction为时间秒以下精度。multi表示该字段为多值字段。
| Java类型 | Field注解 | 推断ttype | 推断配置 | 推断数据库配置 |
|---|---|---|---|---|
| Byte | @Field | BINARY | 无 | tinyint(1) |
| String | @Field | STRING | size=128 | varchar(128) |
List<primitive type> | @Field | STRING | size=1024,multi=true | varchar(1024) |
| Map | @Field | STRING | size=1024 | varchar(1024) |
| Short | @Field | INTEGER | M=5 | smallint(6) |
| Integer | @Field | INTEGER | M=10 | integer(11) |
| Long | @Field | INTEGER | M=19 | bigint(20) |
| BigInteger | @Field | INTEGER | M=64 | decimal(64,0) |
| Float | @Field | FLOAT | M=7,D=2 | float(7,2) |
| Double | @Field | FLOAT | M=15,D=4 | double(15, 4) |
| BigDecimal | @Field | FLOAT | M=64,D=6 | decimal(64,6) |
| Boolean | @Field | BOOLEAN | 无 | tinyint(1) |
| java.util.Date | @Field | DATETIME | fraction=0 | datetime |
| java.util.Date | @Field.Date(type=DateTypeEnum.YEAR) | YEAR | 无 | year |
| java.util.Date | @Field.Date(type=DateTypeEnum.DATE) | DATE | 无 | date |
| java.util.Date | @Field.Date(type=DateTypeEnum.TIME) | TIME | fraction=0 | time |
| java.sql.Timestamp | @Field | DATETIME | fraction=0 | timestamp |
| java.sql.Date | @Field | DATE | 无 | date |
| java.sql.Time | @Field | TIME | fraction=0 | time |
| Long | @Field.Date | DATETIME | fraction=0 | datetime |
| enum implements IEnum | @Field | ENUM | 无 | 根据枚举value类型 |
| primitive type | @Field.Enum(dictionary=数据字典编码) | ENUM | 无 | 根据枚举value类型 |
List<primitive type> | @Field.Enum(dictionary=数据字典编码) | ENUM | multi=true | varchar(512) |
| 模型类 | @Field.Relation | M2O | 无 | text |
| DataMap | @Field.Relation | M2O | 无 | text |
| List<模型类> | @Field.Relation | O2M | multi=true | text |
List<DataMap> | @Field.Relation | O2M | multi=true | text |
(二)安装与更新
通过 @Field.field 配置字段的不可变编码,该编码一经设定便无法修改。后续对字段配置的更新,均以该编码为依据进行检索处理。若修改此注解的配置值,系统将视其为新字段,在存储模型中创建新的数据库表字段,同时将原字段 rename 为废弃字段。
(三)基础配置
1、不可变更字段
使用 immutable 属性可将字段标记为前后端均不可更新,系统会自动忽略针对此类不可变更字段的更新操作。此外,若字段添加了 @Base 注解,其 immutable 属性将自动设为 true。
@Field(displayName = "名称", immutable = true)
private String name;2、字段编码生成器
通过 @Field.Sequence 注解,可便捷地为字段配置编码生成规则。当字段编码为空时,系统将依据预设规则自动生成对应编码,实现数据编码的自动化管理 。如:
@Field.String
@Field(displayName = "编码", unique = true)
@Field.Sequence(sequence = SequenceNameConstants.SEQ, prefix = "C", size = 5, step = 1, initial = 10000)
private String code;提示
在模型层面,编码生成器同样能够借助@Model.Code进行定义。不过,有一点需要特别留意:应用了@Model.Code的模型必须设置code字段,因为该生成器是与code字段绑定的。
@Model.Code(sequence = SequenceNameConstants.DATE_ORDERLY_SEQ,prefix = "P",size=6,step=1,initial = 10000,format = "yyyyMMdd")
public class TestModel extends CodeModel {}3、字段的序列化与反序列化
通过 @Field 注解的 serialize 属性,可灵活配置非字符串类型属性的序列化与反序列化策略。经处理后的数据将以序列化生成的字符串形式,持久化存储至系统中。如:
// 以逗号拼接集合元素序列化,允许存储,支持多值
@Field(displayName = "商品标签", serialize = Field.serialize.COMMA, store = NullableBoolEnum.TRUE, multi = true)
@Field.Advanced(columnDefinition = "varchar(1024)")
private List<String> tags;
// 采用JSON格式序列化,允许存储,关联关系不单独存储
@Field.Text
@Field.Relation(store = false)
@Field(displayName = "JSON序列化", serialize = Field.serialize.JSON, store = NullableBoolEnum.TRUE)
private List<TestRelationModel> list;注意
- 若需持久化字段数据,必须将
Field#store属性显式设置为NullableBoolEnum.TRUE; Field#serialize默认采用 JSON 序列化,可按需切换为其他方式;- 对于包含关联关系的字段(如
list),需将Field.Relation#store设为false,避免重复存储字段值与关联表记录。
字段序列化方式可选项
| 序列化方式 | 说明 | 备注 |
|---|---|---|
| JSON | 采用 JSON 格式进行序列化 | 为@Field.serialize默认配置项,适用于模型相关类型字段序列化 |
| DOT | 将集合元素以点号拼接 | |
| COMMA | 将集合元素以逗号拼接 | |
| BIT | 基于按位与运算,通过 2 次幂数求和实现 | 专用于二进制枚举序列化,无需在@Field.serialize中配置,Oinone 自动识别处理 |
自定义序列化方式
若需自定义序列化逻辑,可通过实现pro.shushi.pamirs.meta.api.core.orm.serialize.Serializer接口创建专属序列化器。完成开发后,在字段配置中,将@Field注解的serialize属性指定为X(X为自定义序列化类型,如示例中为custom),即可应用该自定义序列化器。
@Component
public class CustomSerializer implements Serializer<Object, Object> {
@Override
public Object serialize(String ltype, Object value) {
return value;
}
@Override
public Object deserialize(String ltype, String ltypeT, Object value, String format) {
return value;
}
@Override
public String type() {
return "custom";
}
}默认值的反序列化
在字段上配置defaultValue属性时,系统将依据字段的Ttype、Ltype等类型属性自动执行反序列化。具体规则如下:
- OBJ、STRING、TEXT、HTML——类型保持原值;
- BINARY、INTEGER——转为整数;
- FLOAT、MONEY——转为浮点数;
- DATETIME、DATE、TIME、YEAR——按
Field.Date#format指定格式解析; - BOOLEAN——仅支持
null、true、false; - ENUM——通过
value匹配赋值。
4、多值字段
多值字段特性仅适用于基础数据类型及枚举类型字段。如需将字段配置为多值模式,可通过设置字段的multi属性实现。
@Field(displayName = "名称组", multi = true)
private List<String> name;5、默认值
通过字段的defaultValue配置项,能够为字段设定默认值,具体的反序列化规则可参考 “默认值的反序列化” 章节内容。
@Field(displayName = "名称", defaultValue = "默认值")
private String name;6、前端默认配置
可使用 @Field 注解中的以下属性来配置前端的默认视觉与交互规则,这些规则也能在前端进行重载设置。具体属性如下:
required:用于指定字段是否为必填项。invisible:控制字段是否不可见。priority:表示字段优先级,列表的列会依据此属性进行排序。
7、注解配置 @Field
@Field 字段通用配置
├── displayName 显示名称
├── summary 属性的描述
├── store 是否存储,默认 NullableBoolEnum.NULL 即未选择,会跟进字段的Ttype自行推断
├── multi 是否是多值字段,默认值为false
├── priority 数据库字段优先级
├── serialize 后端序列化函数 SerializeEnum 或者 自定义序列化函数
├── requestSerialize 前端序列化函数 SerializeEnum 或者 自定义序列化函数
├── defaultValue 默认值,支持内置函数
├── required 必填,默认值为false
├── invisible 不可见,默认值为false
├── immutable 不可变更,默认值为false
├── unique 唯一索引,默认值为false
├── index 是否可索引,默认值为false
├── translate 国际化,是否需要翻译,默认值为false
├── immutable 不可变更,默认值为false
└── field 默认使用java属性名
└── value
@Field.Advanced 字段高级属性
├── name api名称,默认使用java属性名
├── column 数据表字段名
├── columnDefinition 数据库字段类型,如果需要自定义不在ttype对应数据库字段类型列表中的类型请使用此字段填写完整数据库字段定义
├── onlyColumn 持久层查询直接返回列名,不做属性名映射
└── copied 是否可被拷贝,默认值为true,在前端复制数据记录的时候是否可被复制。
@Field.PrimaryKey 主键标识
├── value 排序
└── keyGenerator id生成策略,默认:NON走系统规则,可选:AUTO_INCREMENT数据库自增ID、DISTRIBUTION分布式ID
@Field.Version 乐观锁
@Filed.Sequence 编码生成配置
├── sequence 序列生成函数,可选值
- SEQ——自增流水号(不连续)
- ORDERLY——自增强有序流水号(连续)
- DATE_SEQ——日期+自增流水号(不连续)
- DATE_ORDERLY_SEQ——日期+强有序流水号(连续)
- DATE——日期
- UUID——随机32位字符串,包含数字和小写英文字母
├── prefix 前缀
├── suffix 后缀
├── size 长度
├── step 步长(包含流水号有效)
├── initial 起始值(包含流水号有效)
├── format 格式化(包含日期有效)
└── separator 分隔符
@Field.Integer 整型类型
├── M 标度,数字最大位数,maximum
├── min 最小值
└── max 最大值
@Field.Float 浮点类型
├── M 标度,数字最大位数,maximum
├── D 精度,小数位数,decimal
├── min 最小值
└── max 最大值
@Field.Boolean 布尔类型
@Field.String 字符串类型
├── size 字符串长度,单值默认128,多值默认512
├── min 最小值
└── max 最大值
@Field.Text 多行文本类型
├── min 最小值
└── max 最大值
@Field.Date 日期时间、年份、日期、时间等类型
├── type 时间类型
├── format 时间格式
├── fraction 时间精度
├── min 最小值
└── max 最大值
@Field.Money
├── M 标度,数字最大位数,maximum,默认值:65
├── D 精度,小数位数,decimal,默认值:6
├── min 最小值
└── max 最大值
@Field.Html 富文本类型
├── size 字符串长度,默认值:1024
├── min 最小值
└── max 最大值
@Field.Enum 枚举类型
├── dictionary 数据字典编码
├── size 存储字符长度
└── limit 枚举选择数量限制 默认:-1(无限制)
@Field.Related 引用字段
└── value(或related) 配合relation使用,关联模型的字段
@Field.Relation 关系类型通用配置
├── store 关系是否存储,默认为true
├── relationFields 自身模型的关系字段,外键,用于取值作为查询条件查询关联模型,与referenceField的字段一一对应
├── references 关联模型,low code模型没有class可以填此项
├── referenceClass 关联模型class,java模型有class可以填此项
├── referenceFields 关联模型的关联字段,关联模型的唯一索引
├── domainSize 模型筛选可选项每页个数
├── domain 模型筛选,数据查询过滤条件
├── context 上下文,查询时前端传入,JSON字符串
├── search 搜索函数(函数编码)
└── columnSize 序列化存储时的存储长度,默认长度1024
@Field.one2many 一对多
├── limit 关系数量限制,默认为-1(即不限制)
├── pageSize 查询每页个数
├── ordering 排序
├── inverse 反向关联,关联关系存储在一对多关系"一"这一端,默认:false
├── onUpdate 更新关联操作,默认:SET_NULL(设置空值),其他可选:NO_ACTION(不任何操作)\CASCADE(级联操作)\RESTRICT(限制操作)
└── onDelete 更新关联操作,默认:SET_NULL(设置空值),其他可选:NO_ACTION(不任何操作)\CASCADE(级联操作)\RESTRICT(限制操作)
@Field.many2one 多对一
@Field.many2many 多对多
├── through 中间模型,low code模型没有class可以填此项
├── throughClass 中间模型class,java模型有class可以填此项
├── relationFields 中间模型与关系模型的关联字段
├── referenceFields 中间模型与关联模型的关联字段
├── limit 关系数量限制,默认为-1(即不限制)
├── pageSize 查询每页个数
└── ordering 排序
@Field.Page 分页标识
└── value 一对多和多对多关系可以在字段上进行分页配置,默认true
@Field.Override 重写
└── value 重写继承字段(关联关系字段)
8、字段命名规范
| 字段属性 | 默认取值规范 | 命名规则规范 |
|---|---|---|
| name | 默认使用java属性名 | 1. 仅支持数字、字母 2. 必须以小写字母开头 3. 长度必须小于等于128个字符 |
| field | 默认使用java属性名 | 与name使用相同命名规则约束 |
| display_name | 默认使用name属性 | 1. 长度必须小于等于128个字符 |
| lname | 使用java属性名,符合java命名规范,真实的属性名称,无法指定 | 与name使用相同命名规则约束 |
| column | 列名为属性名的小驼峰转下划线格式 | 1. 仅支持数字、字母、下划线 2. 长度必须小于等于128个字符(此限制为系统存储约束,与数据库本身无关) |
| summary | 默认使用displayName属性 | 1. 不能使用分号 2. 长度必须小于等于500个字符 |
(四)字段约束
1、主键
配置模型主键的自动生成规则,可通过 YAML 文件或使用 @Model.Advanced 注解的 keyGenerator 属性来实现。支持的生成规则包括自增序列(AUTO_INCREMENT)以及分布式 ID。若未进行相关配置,系统将不会自动生成主键值。
2、逻辑外键约束
在创建关联关系字段时,可借助 @Field.Relation 注解的 onUpdate 和 onDelete 属性,明确在删除模型或更新模型关系字段值时,关联模型应执行的相应操作。这些操作选项包括 RESTRICT、NO_ACTION、SET_NULL 和 CASCADE,默认值为 SET_NULL。各操作含义如下:
- RESTRICT:若模型与关联模型存在关联记录,引擎将阻止模型关系字段的更新操作,或阻止删除该模型记录。
- NO_ACTION:此操作意味着不进行约束(与数据库约束的定义有所不同)。
- CASCADE:当更新模型关系字段或删除模型时,会级联更新关联模型对应记录的关联字段值,或者级联删除关联模型的对应记录。
- SET_NULL:在更新模型关系字段或删除模型时,若关联模型的对应关联字段允许为
null,则该字段将被置为null;若不允许为null,引擎将阻止对模型的操作。
3、通用校验约束
| 字段业务类型 | size | limit | decimal | mime | min | max |
|---|---|---|---|---|---|---|
| BINARY | 文件类型 | 最小比特位 | 最大比特位 | |||
| INTEGER | 有效数字 | 最小值 | 最大值 | |||
| FLOAT | 有效数字 | 小数位数 | 最小值 | 最大值 | ||
| BOOLEAN | ||||||
| ENUM | 存储字符数 | 多选最多数量 | ||||
| STRING | 存储字符数 | 字符数 | 字符数 | |||
| TEXT | 字符数 | 字符数 | ||||
| HTML | 字符数 | 字符数 | ||||
| MONEY | 有效数字 | 小数位数 | 最小值 | 最大值 | ||
| RELATED |
| 字段业务类型 | fraction | format | min | max |
|---|---|---|---|---|
| DATETIME | 时间精度 | 时间格式 | 最早日期时间 | 最晚日期时间 |
| YEAR | 时间格式 | 最早年份 | 最晚年份 | |
| DATE | 时间格式 | 最早日期 | 最晚日期 | |
| TIME | 时间精度 | 时间格式 | 最早时间 | 最晚时间 |
| 字段业务类型 | size | domainSize | limit | pageSize |
|---|---|---|---|---|
| RELATED | 存储字符数(若序列化存储) | |||
| O2O | 存储字符数(若序列化存储) | 可选项每页个数 | ||
| M2O | 存储字符数(若序列化存储) | 可选项每页个数 | ||
| O2M | 存储字符数(若序列化存储) | 可选项每页个数 | 关系数量限制 | 查询每页个数 |
| M2M | 存储字符数(若序列化存储) | 可选项每页个数 | 关系数量限制 | 查询每页个数 |
4、校验约束 Validation
关于此主题的详细内容,可参考 模型的校验约束(Validation) 相关文档。
三、枚举与数据字典
枚举是列举出一个有穷序列集的所有成员的程序。在元数据中,我们使用数据字典进行描述。
1、协议约定
- 配置要求:枚举需实现
IEnum接口,并使用@Dict注解进行配置。通过设置@Dict注解的dictionary属性,可指定数据字典的唯一编码。 - 前后端交互:在前端展示时,使用枚举的
displayName;在前端与后端进行交互时,前端使用枚举的name,而后端则使用枚举的value,包括默认值的设置也采用枚举的value。 - 存储方式:枚举信息会被存储在元数据的数据字典表中。
- 枚举分类:枚举可分为异常类和业务类两种类型。异常类枚举主要用于定义程序运行过程中的错误提示信息;业务类枚举则用于明确业务中某个字段值的有穷有序集合。
2、可变(可继承)枚举
父枚举定义
以下是父枚举 ParentExtendEnum 的定义代码,它继承自 BaseEnum,并使用 @Dict 注解进行配置。
@Dict(dictionary = ParentExtendEnum.DICTIONARY, displayName = "测试枚举继承父枚举", summary = "测试枚举继承父枚举")
public class ParentExtendEnum extends BaseEnum<ParentExtendEnum, String> {
public static final String DICTIONARY = "test.ParentExtendEnum";
public static final ParentExtendEnum A = create("A", "a", "Aa", "AA");
public static final ParentExtendEnum B = create("B", "b", "Bb", "BB");
public static final ParentExtendEnum C = create("C", "c", "Cc", "CC");
}子枚举定义
下面是子枚举 ChildExtendEnum 的定义代码,它继承自 ParentExtendEnum,同样使用 @Dict 注解进行配置。
@Dict(dictionary = ChildExtendEnum.DICTIONARY, displayName = "测试枚举继承子枚举", summary = "测试枚举继承子枚举")
public class ChildExtendEnum extends ParentExtendEnum {
public static final String DICTIONARY = "test.ChildExtendEnum";
public static final ChildExtendEnum D = create("D", "d", "Dd", "DD");
public static final ChildExtendEnum E = create("E", "e", "Ee", "EE");
public static final ChildExtendEnum F = create("F", "f", "Ff", "FF");
}上述代码展示了 Java 中枚举继承的使用,通过父枚举和子枚举的定义,可以实现枚举的扩展。
3、可变枚举的 Switch API
在 Java 里,直接继承 BaseEnum 能够实现 Java 原生不支持的可变枚举功能。可变枚举具备独特优势,它可以在程序运行期间动态增加非 Java 代码定义的枚举项,并且还支持枚举继承特性。不过,由于可变枚举并非 Java 规范中的标准枚举类型,所以不能使用 switch...case... 语句来处理。但 K2 提供了两种替代方式,即 swithes(无需返回值)和 swithGet(需要返回值),以此实现与 switch...case... 相同的功能和逻辑。
swithes 方法示例
BaseEnum.switches(比较变量, 比较方式/*系统默认提供两种方式:caseName()和caseValue()*/,
cases(枚举列表1).to(() -> {/*逻辑处理*/}),
cases(枚举列表2).to(() -> {/*逻辑处理*/}),
// 可以继续添加更多的 cases
cases(枚举列表N).to(() -> {/*逻辑处理*/}),
defaults(() -> {/*默认逻辑处理*/})
);switchGet 方法示例
BaseEnum.<比较变量类型, 返回值类型>switchGet(比较变量,
比较方式/*系统默认提供两种方式:caseName()和caseValue()*/,
cases(枚举列表1).to(() -> {/*return 逻辑处理的结果*/}),
cases(枚举列表2).to(() -> {/*return 逻辑处理的结果*/}),
// 可以继续添加更多的 cases
cases(枚举列表N).to(() -> {/*return 逻辑处理的结果*/}),
defaults(() -> {/*return 逻辑处理的结果*/})
);比较方式说明
caseName():该方式会使用枚举项的name与比较变量进行匹配比较。caseValue():此方式会使用枚举项的value值与比较变量进行匹配比较。
实际应用示例
以下逻辑展示了如何使用 switchGet 方法判断 ttype 的值。当 ttype 的值为 O2O、O2M、M2O 或 M2M 枚举值时返回 true,否则返回 false。
return BaseEnum.<String, Boolean>switchGet(ttype, caseValue(),
cases(O2O, O2M, M2O, M2M).to(() -> true),
defaults(() -> false)
);通过上述方法,即使是可变枚举,也能灵活地实现类似 switch...case... 的逻辑判断。
4、二进制枚举
二进制枚举概述
二进制枚举要求其枚举项的值为 2 的次幂,并且该值必须大于 0。这种设计使得在进行位运算时可以方便地组合和判断枚举项。
二进制枚举的实现
要定义二进制枚举,需要实现 BitEnum 接口。以下是一个示例代码,展示了如何定义一个名为 TestBitEnum 的二进制枚举:
@Dict(dictionary = TestBitEnum.DICTIONARY, displayName = "测试二进制枚举", summary = "测试二进制枚举")
public class TestBitEnum extends BaseEnum<TestBitEnum, Long> implements BitEnum {
public static final String DICTIONARY = "test.ParentExtendEnum";
// 注意:原代码中 C 的值 3 不是 2 的次幂,这里应修改为 4L
public static final TestBitEnum A = create("A", 1L, "Aa", "AA");
public static final TestBitEnum B = create("B", 2L, "Bb", "BB");
public static final TestBitEnum C = create("C", 4L, "Cc", "CC");
}在上述代码中,TestBitEnum 继承自 BaseEnum 并实现了 BitEnum 接口。同时,每个枚举项的值都是 2 的次幂,符合二进制枚举的定义要求。
警告
需要注意的是,原代码中 C 的值 3L 不是 2 的次幂,这不符合二进制枚举的规则,因此这里将其修改为 4L。
5、兼容 Java Enum 的枚举
在 Java 中,可以直接使用 enum 关键字来声明枚举类型。然而,这种方式存在一定的局限性,即声明的枚举无法继承其他类,也难以进行功能扩展。因此,它仅适用于定义那些固定不变、无需修改的基础枚举场景,一般情况下,并不推荐在大多数项目中使用这种方式。
以下是一个具体的代码示例,展示了如何声明一个名为 TestEnum 的兼容 Java Enum 的枚举:
@Dict(dictionary = TestEnum.dictionary, displayName = "测试枚举")
public enum TestEnum implements IEnum<String> {
enum1("enum1", "枚举1", "枚举1"),
enum2("enum1", "枚举2", "枚举2");
public static final String dictionary = "test.TestEnum";
private final String value;
private final String displayName;
private final String help;
TestEnum(String value, String displayName, String help) {
this.value = value;
this.displayName = displayName;
this.help = help;
}
public String getValue() {
return value;
}
public String getDisplayName() {
return displayName;
}
public String getHelp() {
return help;
}
}6、枚举类型的应用
字段定义的两种方式
对字段值的数据字典进行配置,有以下两种方式:
- 使用枚举类声明字段类型:直接以枚举类来定义字段类型。
- 使用枚举项值类型声明字段类型:若采用此方式,需设置
@Field.Enum注解的dictionary属性,该属性值应为对应数据字典的编码。
@Field.Enum
@Field(displayName = "testEnum")
private TestEnum testEnum;
//当以枚举项值类型声明字段类型时,字段类型与枚举值类型必须严格保持一致。
@Field.Enum(dictionary=TestEnum.dictionary)
@Field(displayName = "testDictionarie")
private String testDictionarie;注意
当以枚举项值类型声明字段类型时,字段类型与枚举值类型必须严格保持一致。
多选枚举
@Field(displayName = "testEnums",multi = true)
private List<TestEnum> testEnums;关联关系常量
使用**#常量#**的形式可定义关联关系常量
@Field.one2many
@Field.Relation(relationFields = {"id", "#DEMO#"}, referenceFields = {"testModelId", "type"})
@Field(displayName = "关联模型")
private List<TestRelationModel> relationModel;四、模型继承
模型继承允许子模型继承父模型的元信息、字段、数据管理器和函数,不同的继承方式适用于不同的业务场景:
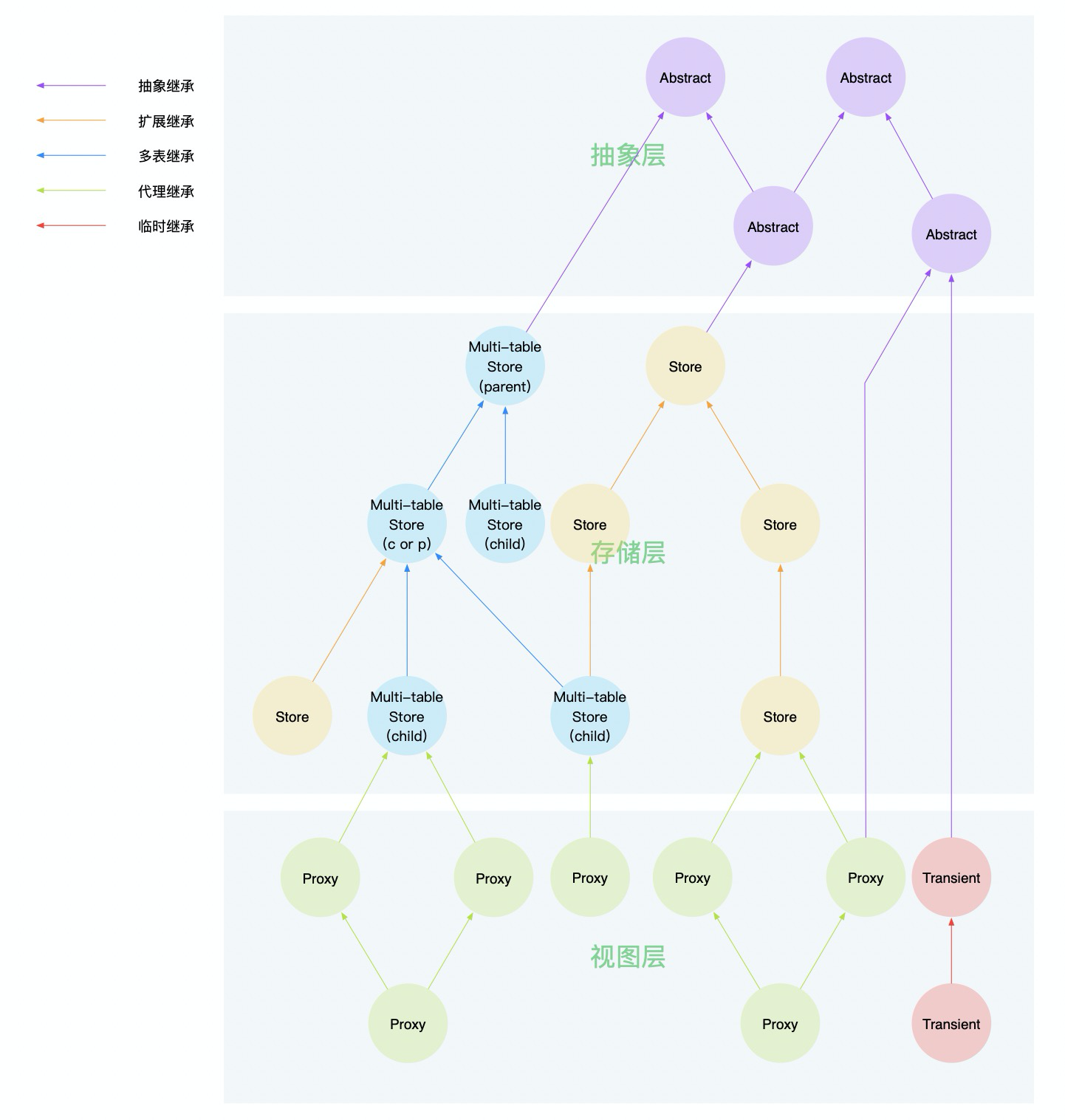
1、抽象继承(ABSTRACT)
抽象基类模型用于存放那些不希望在每个子模型中重复编写的信息。它不会生成对应的数据表来存储数据,仅作为其他模型继承模型可继承域的模板。并且,抽象基类还能继承其他抽象基类。
- 适用场景:主要用于解决公用字段问题,避免在多个子模型中重复定义相同的字段。
- 特点:不生成数据表,仅作为模板供其他模型继承。
子模型继承了抽象父模型称为抽象继承。父模型不会生成表和页面,子模型会继承父模型字段与函数,对应有自己的增删改查页面。
父模型定义
以下是父模型的定义代码,使用 @Model.Advanced(type = ModelTypeEnum.ABSTRACT) 注解将其标记为抽象模型:
@Model.Advanced(type = ModelTypeEnum.ABSTRACT)
@Model.model(PetCommonItem.MODEL_MODEL)
@Model(displayName = "抽象商品", summary = "抽象商品")
public class PetCommonItem extends IdModel {
public static final String MODEL_MODEL = "pet.CommonItem";
// 此处省略字段配置
}子模型定义
子模型通过 extends 关键字继承父模型,示例代码如下:
@Model.model(PetItem.MODEL_MODEL)
@Model(displayName = "宠物商品", summary = "宠物商品")
public class PetItem extends PetCommonItem {
public static final String MODEL_MODEL = "pet.Item";
// 此处省略字段配置
}上述代码展示了抽象继承的实现方式,通过这种方式可以避免在多个子模型中重复定义相同的字段和函数,提高代码的复用性。
2、扩展继承(EXTENDS)
子模型与父模型共用同一张数据表。子模型会继承父模型的字段和函数。在存储模型之间的继承关系时,默认采用的就是扩展继承方式。
- 适用场景:扩展继承是一种实用的模型继承方式,在这种继承关系里,父模型与子模型会共用同一张数据表来存储数据,不过它们会分别拥有各自独立的增删改查操作页面。
- 特点:
- 父子模型共用同一张数据表,表名一致,但模型编码不同。
- 子模型可覆盖父模型的模型管理器、数据排序规则和函数,原模型被扩展成新模型。
父模型定义
以下是父模型 PetItem 的定义代码:
@Model.model(PetItem.MODEL_MODEL)
@Model(displayName = "宠物商品", summary = "宠物商品")
public class PetItem extends PetCommonItem {
private static final long serialVersionUID = -8807269787958617447L;
public static final String MODEL_MODEL = "pet.PetItem";
// 此处省略字段配置
}子模型定义
下面是子模型 PetDogItem 的定义代码,它继承自父模型 PetItem:
@Model.model(PetDogItem.MODEL_MODEL)
@Model(displayName = "宠狗商品", summary = "宠狗商品")
public class PetDogItem extends PetItem {
private static final long serialVersionUID = 5471421982501585732L;
public static final String MODEL_MODEL = "pet.PetDogItem";
// 此处省略字段配置
}通过上述的父模型和子模型定义,我们可以看到在扩展继承中,子模型能够继承父模型的属性和方法,并且由于共用同一张表,能有效减少数据库表的数量,同时各自独立的操作页面又能满足不同的业务交互需求。
3、多表继承(MULTI_TABLE)
多表继承是指在模型继承体系中,父模型与子模型分别生成独立的数据表,并拥有各自对应的增删改查操作页面,通过特定配置实现父子模型间的数据关联与继承关系。
父模型定义
父模型需使用 @Model.MultiTable 注解进行标识,示例如下:
@Model.MultiTable
@Model.model(Context.MODEL_MODEL)
@Model(displayName = "上下文", summary = "上下文")
public class Context extends IdModel {
public static final String MODEL_MODEL = "pet.Context";
// 此处省略字段配置
}配置说明:父模型可通过 Model.MultiTable#typeField 属性,指定用于识别子类类型的字段。若未进行配置,系统将自动生成名为 type 的字段,用以标识子类类型。
子模型定义
子模型需使用 @Model.MultiTableInherited 注解,继承自父模型,示例代码如下:
@Model.MultiTableInherited
@Model.model(SubContext.MODEL_MODEL)
@Model(displayName = "子上下文", summary = "子上下文")
public class SubContext extends Context {
public static final String MODEL_MODEL = "pet.SubContext";
// 此处省略字段配置
}配置说明:子模型可通过 Model.MultiTableInherited#type 属性,指定自身的子类类型,该类型信息将存储在父模型的数据表中。若不设置此属性,系统默认使用子模型的模型编码作为子类类型标识。
4、代理继承(PROXY)
代理继承指的是代理子模型继承父模型的特殊继承方式。在这种模式下,代理子模型不会单独生成数据表,但会拥有独立的增删改查页面。这些页面是在父模型页面的基础上,自动补充了代理子模型新增的传输字段。
父模型定义
父模型可以是存储数据的普通模型,也可以是其他代理模型。以下是一个普通存储模型的示例:
@Model.model(PetItem.MODEL_MODEL)
@Model(displayName = "宠物商品", summary = "宠物商品")
public class PetItem extends PetCommonItem {
public static final String MODEL_MODEL = "pet.Item";
// 此处省略字段配置
}子模型定义
使用 @Model.Advanced(type = ModelTypeEnum.PROXY) 注解将子模型声明为代理模型,示例如下:
@Model.model(PetItemProxy.MODEL_MODEL)
@Model.Advanced(type = ModelTypeEnum.PROXY)
@Model(displayName = "宠物商品代理模型", summary = "宠物商品代理模型")
public class PetItemProxy extends PetItem {
public static final String MODEL_MODEL = "pet.PetItemProxy";
// 新增传输字段
@Field(displayName = "扩展字段")
private String extend;
}关键说明:代理模型中新增的 extend 字段属于传输字段,仅用于数据传递和页面展示,不会在数据库表中生成对应的列。这意味着它只影响前端页面交互,不改变底层数据存储结构,方便在不修改父模型的前提下,快速扩展功能和展示需求。
传输(临时)继承(TRANSIENT)
传输(临时)继承是一种特殊的模型继承方式,当子模型继承传输父模型时,便形成了传输继承。在这种继承关系下,模型不会生成独立的数据表,但会拥有各自的增删改查页面,且列表页不具备后端分页功能。
- 适用场景:主要用于解决使用现有模型进行数据传输的问题。
- 特点:将父模型作为传输模型,可添加传输字段。
父模型定义
父模型需通过 extends TransientModel 来定义为传输模型,示例如下:
@Model.model(PetItemRemark.MODEL_MODEL)
@Model(displayName = "宠物商品备注", summary = "宠物商品备注")
public class PetItemRemark extends TransientModel {
public static final String MODEL_MODEL = "pet.PetItemRemark";
// 此处省略字段配置
}子模型定义
子模型通过 extends 关键字继承父模型,示例代码如下:
@Model.model(PetItemDetail.MODEL_MODEL)
@Model(displayName = "宠物商品详细描述", summary = "宠物商品详细描述")
public class PetItemDetail extends PetItemRemark {
public static final String MODEL_MODEL = "pet.PetItemDetail";
// 此处省略字段配置
}关键说明:继承传输模型的子模型同样属于传输模型。这种方式适用于仅需在内存中临时处理和传递数据的场景,避免了不必要的数据持久化操作,提高了数据处理效率。
五、Common ORM Methods
在 Oinone 使用 ORM 框架时经常会用到的方法,像数据的增删改查、关联查询、事务处理等方法都属于常见的 ORM 方法。
(一)基础CRUD
1、create
- 方法签名:
<T extends AbstractModel> T create() - 来源类:AbstractModel
- 功能描述:创建一条新的数据记录,并返回创建后的模型实例。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 返回值:创建后的模型实例。
- 示例代码:
// 假设 User 类继承自 AbstractModel
User user = new User();
user.setName("John");
user.setAge(25);
User createdUser = user.create();
System.out.println("Created user ID: " + createdUser.getId());2、createOrUpdate
- 方法签名:
Integer createOrUpdate() - 来源类:AbstractModel
- 功能描述:创建或更新数据记录。如果模型中没有主键且没有唯一索引字段,或者主键、唯一索引字段数据为空,则执行新增操作;否则执行更新操作。返回影响的行数。
- 返回值:影响的行数。
- 示例代码:
User user = new User();
user.setName("Charlie");
user.setAge(30);
int rows = user.createOrUpdate();
System.out.println("Rows affected: " + rows);3、createOrUpdateWithResult
- 方法签名:
<T extends AbstractModel> Result<T> createOrUpdateWithResult() - 来源类:AbstractModel
- 功能描述:创建或更新数据记录,并返回包含操作结果的
Result对象。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 返回值:包含操作结果的
Result对象。 - 示例代码:
User user = new User();
user.setName("David");
user.setAge(35);
Result<User> result = user.createOrUpdateWithResult();
if (result.isSuccess()) {
System.out.println("Operation succeeded. Created/Updated user ID: " + result.getData().getId());
} else {
System.out.println("Operation failed. Error message: " + result.getErrorMessage());
}4、updateByPk
- 方法签名:
Integer updateByPk() - 来源类:AbstractModel
- 功能描述:根据主键更新数据记录,模型数据中必须包含主键。返回影响的行数。
- 返回值:影响的行数。
- 示例代码:
User user = new User();
user.setId(1L);
user.setName("Updated John");
int rows = user.updateByPk();
System.out.println("Rows affected: " + rows);5、updateByUnique
- 方法签名:
Integer updateByUnique() - 来源类:AbstractModel
- 功能描述:根据主键与唯一索引更新数据记录,模型数据中必须包含主键或至少一个唯一索引。返回影响的行数。
- 返回值:影响的行数。
- 示例代码:
User user = new User();
user.setUniqueField("unique_value");
user.setName("Updated User");
int rows = user.updateByUnique();
System.out.println("Rows affected: " + rows);6、updateByEntity
- 方法签名:
<T extends AbstractModel> Integer updateByEntity(T entity, T query) - 来源类:AbstractModel
- 功能描述:根据实体条件更新数据记录,
entity为更新的实体,query为更新条件。返回影响的行数。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
entity- 更新实体。query- 更新条件。
- 返回值:影响的行数。
- 示例代码:
User updateEntity = new User();
updateEntity.setName("New Name");
User queryEntity = new User();
queryEntity.setAge(25);
int rows = user.updateByEntity(updateEntity, queryEntity);
System.out.println("Rows affected: " + rows);7、updateByWrapper
- 方法签名:
<T extends AbstractModel> Integer updateByWrapper(T entity, IWrapper<T> updateWrapper) - 来源类:AbstractModel
- 功能描述:根据条件包装器更新数据记录,
entity为更新的实体,updateWrapper为更新条件包装器。返回影响的行数。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
entity- 更新实体。updateWrapper- 更新条件包装器。
- 返回值:影响的行数。
- 示例代码:
User updateEntity = new User();
updateEntity.setName("Updated Name");
IWrapper<User> updateWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
int rows = user.updateByWrapper(updateEntity, updateWrapper);
System.out.println("Rows affected: " + rows);8、deleteByPk
- 方法签名:
Boolean deleteByPk() - 来源类:AbstractModel
- 功能描述:根据主键删除单条记录,模型数据中必须包含主键。返回删除结果。
- 返回值:删除成功返回
true,否则返回false。 - 示例代码:
User user = new User();
user.setId(1L);
boolean deleted = user.deleteByPk();
System.out.println("Delete success: " + deleted);9、deleteByUnique
- 方法签名:
Boolean deleteByUnique() - 来源类:AbstractModel
- 功能描述:根据主键或唯一索引删除单条记录,模型数据中必须包含主键或者至少一个唯一索引。返回删除结果。
- 返回值:删除成功返回
true,否则返回false。 - 示例代码:
User user = new User();
user.setUniqueField("unique_value");
boolean deleted = user.deleteByUnique();
System.out.println("Delete success: " + deleted);10、deleteByEntity
- 方法签名:
Integer deleteByEntity() - 来源类:AbstractModel
- 功能描述:根据实体条件删除记录,返回删除的行数。
- 返回值:删除的行数。
- 示例代码:
User queryEntity = new User();
queryEntity.setAge(25);
int rows = queryEntity.deleteByEntity();
System.out.println("Rows deleted: " + rows);11、deleteByWrapper
- 方法签名:
<T extends AbstractModel> Integer deleteByWrapper(IWrapper<T> queryWrapper) - 来源类:AbstractModel
- 功能描述:根据条件包装器删除记录,返回删除的行数。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
queryWrapper- 删除条件包装器。 - 返回值:删除的行数。
- 示例代码:
IWrapper<User> queryWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
int rows = user.deleteByWrapper(queryWrapper);
System.out.println("Rows deleted: " + rows);(二)条件查询与分页
1、queryByPk
- 方法签名:
<T extends AbstractModel> T queryByPk() - 来源类:AbstractModel
- 功能描述:根据主键查询单条记录,模型数据中必须包含主键。返回查询到的模型实例。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 返回值:查询到的模型实例,如果未找到则返回
null。 - 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = user.queryByPk();
if (queriedUser != null) {
System.out.println("Queried user name: " + queriedUser.getName());
} else {
System.out.println("User not found.");
}2、queryOne
- 方法签名:
<T extends AbstractModel> T queryOne() - 来源类:AbstractModel
- 功能描述:根据主键或唯一索引查询单条记录,模型数据中必须包含主键或唯一索引,查出多条记录会抛异常。返回查询到的模型实例。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 返回值:查询到的模型实例,如果未找到则返回
null。 - 示例代码:
User user = new User();
user.setUniqueField("unique_value");
User queriedUser = user.queryOne();
if (queriedUser != null) {
System.out.println("Queried user name: " + queriedUser.getName());
} else {
System.out.println("User not found.");
}3、queryOneByWrapper
- 方法签名:
<T extends AbstractModel> T queryOneByWrapper(IWrapper<T> queryWrapper) - 来源类:AbstractModel
- 功能描述:根据条件包装器查询单条记录,查出多条记录会抛异常。返回查询到的模型实例。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
queryWrapper- 查询条件包装器。 - 返回值:查询到的模型实例,如果未找到则返回
null。 - 示例代码:
IWrapper<User> queryWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
User queriedUser = user.queryOneByWrapper(queryWrapper);
if (queriedUser != null) {
System.out.println("Queried user name: " + queriedUser.getName());
} else {
System.out.println("User not found.");
}4、queryList
- 方法签名:
<T extends AbstractModel> List<T> queryList() - 来源类:AbstractModel
- 功能描述:按实体条件查询数据列表,返回满足条件的数据记录列表。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 返回值:满足条件的数据记录列表。
- 示例代码:
User queryEntity = new User();
queryEntity.setAge(25);
List<User> userList = queryEntity.queryList();
for (User user : userList) {
System.out.println("User name: " + user.getName());
}5、queryList(int batchSize)
- 方法签名:
<T extends AbstractModel> List<T> queryList(int batchSize) - 来源类:AbstractModel
- 功能描述:按实体条件查询数据列表,可以设置
batchSize来分批次查询。返回满足条件的数据记录列表。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
batchSize- 每批次查询的记录数。 - 返回值:满足条件的数据记录列表。
- 示例代码:
User queryEntity = new User();
queryEntity.setAge(25);
List<User> userList = queryEntity.queryList(100);
for (User user : userList) {
System.out.println("User name: " + user.getName());
}6、queryList(IWrapper<T> queryWrapper)
- 方法签名:
<T extends AbstractModel> List<T> queryList(IWrapper<T> queryWrapper) - 来源类:AbstractModel
- 功能描述:按条件包装器查询数据列表,返回满足条件的数据记录列表。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
queryWrapper- 查询条件包装器。 - 返回值:满足条件的数据记录列表。
- 示例代码:
IWrapper<User> queryWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
List<User> userList = user.queryList(queryWrapper);
for (User user : userList) {
System.out.println("User name: " + user.getName());
}7、queryList(Pagination<T> page, T query)
- 方法签名:
<T extends AbstractModel> List<T> queryList(Pagination<T> page, T query) - 来源类:AbstractModel
- 功能描述:按分页和实体条件查询数据列表,返回查询分页结果。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
page- 分页对象。query- 查询实体。
- 返回值:查询分页结果。
- 示例代码:
Pagination<User> page = new Pagination<>(1, 10);
User queryEntity = new User();
queryEntity.setAge(25);
List<User> userList = user.queryList(page, queryEntity);
for (User user : userList) {
System.out.println("User name: " + user.getName());
}8、queryListByWrapper
- 方法签名:
<T extends AbstractModel> List<T> queryListByWrapper(Pagination<T> page, IWrapper<T> queryWrapper) - 来源类:AbstractModel
- 功能描述:按分页条件查询数据列表,返回查询分页结果。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
page- 分页对象。queryWrapper- 查询条件包装器。
- 返回值:查询分页结果。
- 示例代码:
Pagination<User> page = new Pagination<>(1, 10);
IWrapper<User> queryWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
List<User> userList = user.queryListByWrapper(page, queryWrapper);
for (User user : userList) {
System.out.println("User name: " + user.getName());
}9、queryPage
- 方法签名:
<T extends AbstractModel> Pagination<T> queryPage(Pagination<T> page, IWrapper<T> queryWrapper) - 来源类:AbstractModel
- 功能描述:按条件查询数据列表,并返回分页对象,包含总记录数、总页数等信息。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
page- 分页对象。queryWrapper- 查询条件包装器。
- 返回值:包含分页信息的
Pagination对象。 - 示例代码:
Pagination<User> page = new Pagination<>(1, 10);
IWrapper<User> queryWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
Pagination<User> result = user.queryPage(page, queryWrapper);
System.out.println("Total records: " + result.getTotal());
System.out.println("Total pages: " + result.getPages());
for (User user : result.getRecords()) {
System.out.println("User name: " + user.getName());
}10、count
- 方法签名:
Long count() - 来源类:AbstractModel
- 功能描述:按实体条件查询数据数量,返回满足查询条件的记录数量。
- 返回值:满足查询条件的记录数量。
- 示例代码:
User queryEntity = new User();
queryEntity.setAge(25);
long count = queryEntity.count();
System.out.println("Record count: " + count);11、count(IWrapper<T> queryWrapper)
- 方法签名:
<T extends AbstractModel> Long count(IWrapper<T> queryWrapper) - 来源类:AbstractModel
- 功能描述:按条件包装器查询数据数量,返回满足查询条件的记录数量。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
queryWrapper- 查询条件包装器。 - 返回值:满足查询条件的记录数量。
- 示例代码:
IWrapper<User> queryWrapper = new QueryWrapper<User>().from(User.MODEL_MODEL)
.eq("age", 25);
long count = user.count(queryWrapper);
System.out.println("Record count: " + count);(三)字段级关联操作
1、fieldQuery Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> T fieldQuery(Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:关联关系字段查询,通过
Getter方法指定关联关系字段。返回包含查询字段值的模型数据。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
getter- 关联关系字段的Getter方法,例如Model::getField。 - 返回值:包含查询字段值的模型数据。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
queriedUser.fieldQuery(User::getRelationField);
if (queriedUser.getRelationField() != null) {
System.out.println("Relation field value: " + queriedUser.getRelationField());
}2、fieldQuery
- 方法签名:
<T extends AbstractModel> T fieldQuery(String fieldName) - 来源类:AbstractModel
- 功能描述:关联关系字段查询,通过字段名指定关联关系字段。返回包含查询字段值的模型数据。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
fieldName- Java 字段名称。 - 返回值:包含查询字段值的模型数据。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
queriedUser.fieldQuery("relationField");
if (queriedUser.getRelationField() != null) {
System.out.println("Relation field value: " + queriedUser.getRelationField());
}3、fieldSave Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> T fieldSave(Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:新增或更新关联关系字段(增量),根据指令系统的数据提交策略新增或更新关联关系字段。返回包含更新字段值的模型数据。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
getter- 关联关系字段的Getter方法,例如Model::getField。 - 返回值:包含更新字段值的模型数据。
- 示例代码:
User user = new User();
user.setName("John");
user.setAge(25);
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
user.setO2MField(o2mObjects);
//先保存one这边的记录
user.create();
//再保存one2many,many2many的关系字段
user.fieldSave(User::getO2MField);4、fieldSave
- 方法签名:
<T extends AbstractModel> T fieldSave(String fieldName) - 来源类:AbstractModel
- 功能描述:新增或更新关联关系字段(增量),通过字段名指定关联关系字段。返回包含更新字段值的模型数据。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
fieldName- Java 字段名称。 - 返回值:包含更新字段值的模型数据。
- 示例代码:
User user = new User();
user.setName("John");
user.setAge(25);
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
user.setO2MField(o2mObjects);
//先保存one这边的记录
user.create();
//再保存one2many,many2many的关系字段
user.fieldSave("o2mField");5、fieldSaveOnCascade Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> T fieldSaveOnCascade(Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:新增或更新关联关系字段(全量),并按照字段级联策略处理旧记录的关系数据(如:删除、SET_NULL),通过
Getter方法指定关联关系字段。返回包含更新字段值的模型数据。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
getter- 关联关系字段的Getter方法,例如Model::getField。 - 返回值:包含更新字段值的模型数据。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
queriedUser.setO2MField(o2mObjects);
//如过使用fieldSave方法,需要自行处理关系差量如:删除与旧记录的关联
queriedUser.fieldSaveOnCascade(User::getO2MField);6、fieldSaveOnCascade
- 方法签名:
<T extends AbstractModel> T fieldSaveOnCascade(String fieldName) - 来源类:AbstractModel
- 功能描述:新增或更新关联关系字段(全量),并按照字段级联策略处理旧记录的关系数据(如:删除、SET_NULL),通过
Getter方法指定关联关系字段。返回包含更新字段值的模型数据。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
fieldName- Java 字段名称。 - 返回值:包含更新字段值的模型数据。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
queriedUser.setO2MField(o2mObjects);
//如过使用fieldSave方法,需要自行处理关系差量如:删除与旧记录的关联
queriedUser.fieldSaveOnCascade("o2MField");7、relationDelete Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> T relationDelete(Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:删除关联关系(增量),通过
Getter方法指定关联关系字段。返回模型数据。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
getter- 关联关系字段的Getter方法,例如Model::getField。 - 返回值:模型数据。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
queriedUser.fieldQuery(User::getO2MField);
queriedUser.relationDelete(User::getO2MField);8、relationDelete
- 方法签名:
<T extends AbstractModel> T relationDelete(String fieldName) - 来源类:AbstractModel
- 功能描述:删除关联关系(增量),通过字段名指定关联关系字段。返回模型数据。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
fieldName- Java 字段名称。 - 返回值:模型数据。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
queriedUser.fieldQuery(User::getO2MField);
queriedUser.relationDelete("o2MField");9、listFieldQuery Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> List<T> listFieldQuery(List<T> dataList, Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:批量关联关系字段查询,通过
Getter方法指定关联关系字段。返回包含查询字段值的模型数据列表。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 当前模型数据列表。getter- 关联关系字段的Getter方法,例如Model::getField。
- 返回值:包含查询字段值的模型数据列表。
- 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setId(1L);
User queriedUser1 = = user1.queryByPk();
userList.add(queriedUser1);
User user2 = new User();
user2.setId(2L);
User queriedUser2 = = user2.queryByPk();
userList.add(queriedUser2);
List<User> queriedUsers = new User().listFieldQuery(userList, User::getRelationField);
for (User queriedUser : queriedUsers) {
System.out.println("Relation field value for user " + queriedUser.getId() + ": " + queriedUser.getRelationField());
}10、listFieldQuery
- 方法签名:
<T extends AbstractModel> List<T> listFieldQuery(List<T> dataList, String fieldName) - 来源类:AbstractModel
- 功能描述:批量关联关系字段查询,通过字段名指定关联关系字段。返回包含查询字段值的模型数据列表。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 当前模型数据列表。fieldName- Java 字段名称。
- 返回值:包含查询字段值的模型数据列表。
- 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setId(1L);
User queriedUser1 = = user1.queryByPk();
userList.add(queriedUser1);
User user2 = new User();
user2.setId(2L);
User queriedUser2 = = user2.queryByPk();
userList.add(queriedUser2);
List<User> queriedUsers = new User().listFieldQuery(userList,"relationField");
for (User queriedUser : queriedUsers) {
System.out.println("Relation field value for user " + queriedUser.getId() + ": " + queriedUser.getRelationField());
}11、listFieldSave Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> List<T> listFieldSave(List<T> dataList, Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:批量新增或更新关联关系字段记录,通过
Getter方法指定关联关系字段。返回包含更新字段值的模型数据列表。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 当前模型数据列表。getter- 关联关系字段的Getter方法,例如Model::getField。
- 返回值:包含更新字段值的模型数据列表。
- 示例代码:
User user = new User();
user.setName("John");
user.setAge(25);
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
user.setO2MField(o2mObjects);
//先保存one这边的记录
user.create();
//再保存one2many,many2many的关系字段
List<User> userList = new ArrayList<>();
userList.add(user);
List<User> updatedUsers = new User().listFieldSave(userList, User::getO2MField);12、listFieldSave
- 方法签名:
<T extends AbstractModel> List<T> listFieldSave(List<T> dataList, String fieldName) - 来源类:AbstractModel
- 功能描述:批量新增或更新关联关系字段记录,通过字段名指定关联关系字段。返回包含更新字段值的模型数据列表。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 当前模型数据列表。fieldName- Java 字段名称。
- 返回值:包含更新字段值的模型数据列表。
- 示例代码:
User user = new User();
user.setName("John");
user.setAge(25);
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
user.setO2MField(o2mObjects);
//先保存one这边的记录
user.create();
//再保存one2many,many2many的关系字段
List<User> userList = new ArrayList<>();
userList.add(user);
List<User> updatedUsers = new User().listFieldSave(userList, "o2MField");13、listFieldSaveOnCascade Lambda 表达式指定字段
- 方法签名:
<T extends AbstractModel> List<T> fieldSaveOnCascade(List<T> dataList, Getter<T, ?> getter) - 来源类:AbstractModel
- 功能描述:批量新增或更新关联关系字段(全量),并按照字段级联策略处理旧记录的关系数据(如:删除、SET_NULL),通过
Getter方法指定关联关系字段。返回包含更新字段值的模型数据列表。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 当前模型数据列表。getter- 关联关系字段的Getter方法,例如Model::getField。
- 返回值:包含更新字段值的模型数据列表。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
queriedUser.setO2MField(o2mObjects);
List<User> userList = new ArrayList<>();
userList.add(queriedUser);
//如过使用listFieldSave方法,需要自行处理关系差量如:删除与旧记录的关联
new User().listFieldSaveOnCascade(userList,User::getO2MField);14、listFieldSaveOnCascade
- 方法签名:
<T extends AbstractModel> List<T> fieldSaveOnCascade(List<T> dataList, String fieldName) - 来源类:AbstractModel
- 功能描述:批量新增或更新关联关系字段(全量),并按照字段级联策略处理旧记录的关系数据(如:删除、SET_NULL),通过字段名指定关联关系字段。返回包含更新字段值的模型数据列表。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 当前模型数据列表。fieldName- Java 字段名称。
- 返回值:包含更新字段值的模型数据列表。
- 示例代码:
User user = new User();
user.setId(1L);
User queriedUser = = user.queryByPk();
List<RelationObject> o2mObjects = new ArrayList<RelationObject>();
RelationObject relationObject = new RelationObject()
o2mObjects.add(relationObject);
queriedUser.setO2MField(o2mObjects);
List<User> userList = new ArrayList<>();
userList.add(queriedUser);
//如过使用listFieldSave方法,需要自行处理关系差量如:删除与旧记录的关联
new User().listFieldSaveOnCascade(userList,"o2MField");(四)批量操作
1、createBatch
- 方法签名:
<T extends AbstractModel> List<T> createBatch(List<T> dataList) - 来源类:AbstractModel
- 功能描述:批量创建数据记录,返回创建后的模型列表。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 待创建的数据列表。 - 返回值:创建后的模型列表。
- 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setName("Alice");
user1.setAge(22);
userList.add(user1);
User user2 = new User();
user2.setName("Bob");
user2.setAge(28);
userList.add(user2);
List<User> createdUsers = user.createBatch(userList);
System.out.println("Created " + createdUsers.size() + " users.");2、createOrUpdateBatch
- 方法签名:
<T extends AbstractModel> Integer createOrUpdateBatch(List<T> dataList) - 来源类:AbstractModel
- 功能描述:批量创建或更新数据记录,返回影响的行数。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 待操作的数据列表。 - 返回值:影响的行数。
- 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setName("Eve");
user1.setAge(26);
userList.add(user1);
User user2 = new User();
user2.setName("Frank");
user2.setAge(32);
userList.add(user2);
int rows = user.createOrUpdateBatch(userList);
System.out.println("Rows affected: " + rows);3、createOrUpdateBatchWithResult
- 方法签名:
<T extends AbstractModel> Result<List<T>> createOrUpdateBatchWithResult(List<T> dataList) - 来源类:AbstractModel
- 功能描述:批量创建或更新数据记录,并返回包含操作结果的
Result对象,其中包含操作后的模型列表。 - 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 待操作的数据列表。 - 返回值:包含操作结果的
Result对象,其中包含操作后的模型列表。 - 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setName("Grace");
user1.setAge(24);
userList.add(user1);
User user2 = new User();
user2.setName("Henry");
user2.setAge(31);
userList.add(user2);
Result<List<User>> result = user.createOrUpdateBatchWithResult(userList);
if (result.isSuccess()) {
System.out.println("Operation succeeded. Created/Updated " + result.getData().size() + " users.");
} else {
System.out.println("Operation failed. Error message: " + result.getErrorMessage());
}4、updateBatch
- 方法签名:
<T extends AbstractModel> Integer updateBatch(List<T> dataList) - 来源类:AbstractModel
- 功能描述:批量更新数据记录,模型数据中必须包含主键或至少一个唯一索引。返回影响的行数。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 待更新的数据列表。 - 返回值:影响的行数。
- 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setId(1L);
user1.setName("Updated Alice");
userList.add(user1);
User user2 = new User();
user2.setId(2L);
user2.setName("Updated Bob");
userList.add(user2);
int rows = user.updateBatch(userList);
System.out.println("Rows affected: " + rows);5、deleteByPks
- 方法签名:
<T extends AbstractModel> Boolean deleteByPks(List<T> dataList) - 来源类:AbstractModel
- 功能描述:根据主键批量删除记录,模型数据中必须包含主键。返回删除结果。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 待删除的数据列表。 - 返回值:删除成功返回
true,否则返回false。 - 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setId(1L);
userList.add(user1);
User user2 = new User();
user2.setId(2L);
userList.add(user2);
boolean deleted = user.deleteByPks(userList);
System.out.println("Delete success: " + deleted);6、deleteByUniques
- 方法签名:
<T extends AbstractModel> Boolean deleteByUniques(List<T> dataList) - 来源类:AbstractModel
- 功能描述:根据主键或唯一索引批量删除记录,模型数据中必须包含主键或者至少一个唯一索引。返回删除结果。
- 泛型参数:
<T>- 模型类型,必须是AbstractModel的子类。 - 参数:
dataList- 待删除的数据列表。 - 返回值:删除成功返回
true,否则返回false。 - 示例代码:
List<User> userList = new ArrayList<>();
User user1 = new User();
user1.setUniqueField("unique_value_1");
userList.add(user1);
User user2 = new User();
user2.setUniqueField("unique_value_2");
userList.add(user2);
boolean deleted = user.deleteByUniques(userList);
System.out.println("Delete success: " + deleted);(五)QueryWrapper 与 LambdaQueryWrapper 基础用法
1、初始化与链式调用
// 初始化 QueryWrapper(指定实体类型)、LambdaQueryWrapper(指定实体类型)
// 没有传入模型对象的,一定要记住要用调用.from()来传递模型编码
QueryWrapper<User> wrapper1 = Pops.query(new User());
QueryWrapper<User> wrapper2 = Pops.<User>query().from(User.MODEL_MODEL);
QueryWrapper<User> wrapper3= new QueryWrapper<User>().from(User.MODEL_MODEL);
LambdaQueryWrapper<User> lambdaWrapper1 = Pops.lambdaQuery(new User());
LambdaQueryWrapper<User> lambdaWrapper2 = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
LambdaQueryWrapper<User> lambdaWrapper3= new LambdaQueryWrapper<User>().from(User.MODEL_MODEL);
// 链式构建条件
wrapper1
.eq("age", 25) // age = 25
.like("name", "张%") // name LIKE '张%'
.orderBy("createDate", false); // 按 createDate 降序2、常用条件方法
| 方法 | 说明 | 示例 |
|---|---|---|
eq(column, value) | 等于 | .eq("status", 1) |
ne(column, value) | 不等于 | .ne("deleted", 0) |
gt(column, value)ge(column, value)lt(column, value)le(column, value) | 大于 大于等于 小于 小于等于 | .gt("createDate", "2023-01-01") |
isNull(column)isNotNull(column) | 为空 不为空 | .isNull("email") |
in(column, collection) | IN 查询 | .in("id", Arrays.asList(1,2,3)) |
between(column, value1,value2) | 闭区间查询 | .between(User::getCreateDate, "2023-01-01", "2023-12-31") |
like(column, value) | 模糊匹配 | .like("email", "%@example.com") |
orderBy(column, isAsc) | 排序 | .orderBy("age", true) |
and/or(consumer) | 嵌套条件 | .or(sub -> sub.eq("status", 1)) |
groupBy(columns) | 分组 | .groupBy("age","status") |
// 示例:查询年龄 25 岁且姓名以 "张" 开头的用户
QueryWrapper<User> wrapper = Pops.<User>query().from(User.MODEL_MODEL);
wrapper.eq("age", 25).like("name", "张%");
List<User> users = new User().queryList(wrapper);(六)LambdaQueryWrapper 高级用法
1、初始化与类型安全
// 初始化 LambdaQueryWrapper(避免字段名硬编码)
LambdaQueryWrapper<User> lambdaWrapper = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
// 通过 Lambda 表达式指定字段
lambdaWrapper
.eq(User::getAge, 25) // 编译时检查字段存在性
.like(User::getName, "张%")
.orderByDesc(User::getCreateDate);2、复杂条件组合
// 嵌套条件:年龄 > 30 或 (姓名包含 "李" 且状态为激活)
lambdaWrapper
.gt(User::getAge, 30)
.or(sub -> sub
.like(User::getName, "李%")
.eq(User::getStatus, "active")
);3、动态条件构建
// 动态添加条件(根据业务逻辑)
String searchName = "王";
Integer minAge = 20;
LambdaQueryWrapper<User> wrapper = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
if (searchName != null) {
wrapper.like(User::getName, searchName + "%");
}
if (minAge != null) {
wrapper.ge(User::getAge, minAge);
}
List<User> users = new User().queryList(wrapper);4、拼接 sql
// apply sql中要用数据库字段的column,而不是模型中的字段名
LambdaQueryWrapper<User> wrapper = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
// wrapper.apply("date_format(dateColumn,'%Y-%m-%d') = '2008-08-08'")
wrapper.apply("date_format(create_date,'%Y-%m-%d') = {0}", LocalDate.now())
List<User> users = new User().queryList(wrapper);(七)分页查询实战
1、基础分页
// 分页参数:第 2 页,每页 10 条
Pagination<User> page = new Pagination<>(2, 10);
// 构建条件
LambdaQueryWrapper<User> wrapper = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
wrapper.eq(User::getDepartmentId, 5);
// 执行分页查询
page = new User().queryPage(page, wrapper);
// 获取结果
List<User> userList = page.getContent();
long total = page.getTotal();2、分页 + 排序
LambdaQueryWrapper<User> wrapper = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
wrapper
.between(User::getCreateDate, "2023-01-01", "2023-12-31")
.orderByAsc(User::getAge) // 年龄升序
.orderByDesc(User::getId); // ID 降序
// 分页参数:第 1 页,每页 10 条
Pagination<User> page = new Pagination<>(1, 10);
Pagination<User> page = new User().queryPage(page, wrapper);3、分页时关闭 count 查询(性能优化)
Pagination<User> page = new Pagination<>(1, 10);
page.setSearchCount(false); // 禁用 SELECT COUNT(*)4、完整示例:多条件分页查询
// 1. 构建分页参数
Pagination<User> page = new Pagination<>(1, 10);
// page.setSearchCount(true); // 默认返回总记录数,不需要设置
// 2. 构建 Lambda 条件
LambdaQueryWrapper<User> wrapper = Pops.<User>lambdaQuery().from(User.MODEL_MODEL);
wrapper
.ge(User::getAge, 18) // 年龄 >= 18
.le(User::getAge, 30) // 年龄 <= 30
.in(User::getRole, Arrays.asList("admin", "editor")) // 角色 IN 查询
.orderByAsc(User::getAge) // 年龄升序
.orderByDesc(User::getCreateDate); // 创建时间降序
// 3. 执行分页查询
page = new User().queryPage(page, wrapper);
// 4. 获取结果
List<User> userList = page.getContent();
long total = page.getTotal();5、list查询使用技巧
BatchSizeHintApi
在处理大量数据查询时,合理设置查询的批量数量可以优化性能,减少内存消耗和网络传输压力。比如在分页查询或批量数据处理场景中,根据数据量和系统资源情况,精确控制每次查询返回的数据量。
public static BatchSizeHintApi use(Integer batchSize) {
// 具体实现
}use(Integer batchSize):通过传入一个整数值来指定查询的批量数量。该整数值代表每次查询返回的数据量,特殊值-1表示不分页,一次性返回所有符合条件的数据。
BatchSizeHintApi 使用示例
在try块内,所有查询操作都会按照指定的batchSize进行查询。
try (BatchSizeHintApi batchSizeHintApi = BatchSizeHintApi.use(-1)) {
PetShopProxy data2 = data.queryById();
data2.fieldQuery(PetShopProxy::getPetTalents);
}六、持久层操作
(一)批量操作
批量操作涵盖批量创建与批量更新两种模式,系统默认采用 batchCommit 作为提交类型。目前支持以下四种提交类型,配置参考:批量操作配置。
1、运行时配置
系统批量更新提交方式默认规则:
- 非乐观锁模型用
batchCommit(单脚本批量提交,不返回影响行数); - 乐观锁模型用
useAndJudgeAffectRows(逐条提交并校验行数,不一致则抛异常)。 支持运行时修改提交方式:
Spider.getDefaultExtension(BatchApi.class).run(() -> {
更新逻辑
}, 批量提交类型枚举);2、运行时校正
系统会根据模型配置在运行时自动校正批量提交类型,具体规则如下:
- 批量新增场景:若模型配置了数据库自增主键,且批量提交类型设为
batchCommit,系统会自动将其变更为collectionCommit。因为使用batchCommit时需单条提交才能获取正确的主键返回值,这会降低性能。 - 批量更新场景:若模型配置了乐观锁,且批量提交类型设为
collectionCommit或batchCommit,系统会自动将其变更为useAndJudgeAffectRows。若希望系统不进行批量提交类型变更处理,可选择使乐观锁失效。
(二)乐观锁
在处理可能遭遇并发修改的数据时,通常需要进行并发控制。数据库层面常见的并发控制方式有两种:悲观锁和乐观锁。oinone 对乐观锁提供了一定的支持。
1、乐观锁定义方式
乐观锁有以下两种定义方式:
- 快捷继承:通过继承
VersionModel,可以快速构建一个带有乐观锁、唯一编码code且主键为id的模型。 - 注解标识:在字段上使用
@Field.Version注解,可标识该模型在更新数据时使用乐观锁。
2、异常处理
当更新操作的实际影响行数与传入参数的数量不一致时,系统会抛出异常,错误码为 10150024。在批量更新数据时,为了准确返回实际影响行数,系统会将批量提交改为循环单条数据提交更新,这可能会导致一定的性能损失。
3、乐观锁失效处理
若一个模型在某些场景下需要使用乐观锁更新数据,而在另一些场景下不需要,可以使用以下代码在特定场景下使乐观锁失效:
PamirsSession.directive().disableOptimisticLocker();
try {
// 更新逻辑
} finally {
PamirsSession.directive().enableOptimisticLocker();
}4、不抛乐观锁异常处理
若不想抛出乐观锁异常,可将批量提交类型设置为 useAffectRows,这样就能由外层逻辑自主判断返回的实际影响行数。示例代码如下:
Spider.getDefaultExtension(BatchApi.class).run(() -> {
// 更新逻辑,返回实际影响行数
}, BatchCommitTypeEnum.useAffectRows);通过上述方式,你可以灵活地运用乐观锁进行并发控制,同时根据实际需求处理异常和性能问题。
警告
使用乐观锁时,单记录更新操作要手动判断影响行数。若未判断,更新失败时程序不会报错,而batch接口则会自动校验并报错 。
警告:对可能产生的严重后果的提醒
自定义页面使用乐观锁,需在视图 xml 中配置optVersion字段(可设为隐藏),否则校验失败。
七、异常处理
(一)模块异常枚举定义
使用 @Errors 注解定义模块专属异常枚举,示例:
@Errors(displayName = "xxx模块错误枚举")
public enum XxxxExpEnumerate implements ExpBaseEnum {
CUSTOM_ERROR(ERROR_TYPE.SYSTEM_ERROR, xxxxxxxx,""),
SYSTEM_ERROR(ERROR_TYPE.SYSTEM_ERROR, xxxxxxxx, "系统异常");
private ERROR_TYPE type;
private int code;
private String msg;
XxxxExpEnumerate(ERROR_TYPE type, int code, String msg) {
this.type = type;
this.code = code;
this.msg = msg;
}
@Override public ERROR_TYPE type() { return type; }
@Override public int code() { return code; }
@Override public String msg() { return msg; }
}(二)异常抛出
通过 PamirsException.construct 方法抛出异常:
throw PamirsException.construct(XxxxExpEnumerate.CUSTOM_ERROR).appendMsg("异常附带必要的信息,非必须").errThrow();