树(Tree)
一、视图特征
- 视图类型:树视图(TREE)
- 数据类型:树(Tree)
- DSL 特征:仅描述树层级信息。
- 数据结构通用行为:
- 查询行为:一次性加载、按层级懒加载、搜索。
- 交互行为:单选、多选。
- 树组件行为:
- 交互行为:展开视图等。
- 常用接口:(
base.UiTreeNode)- fetchAll:一次性加载。(
queryListByWrapper) - fetchChildren:按层级懒加载。(
queryPage) - queryKeywords4Tree:搜索。(
queryListByWrapper) - queryKeywords4InnerSelfTree:级联组件在单个卡片中的搜索。(
queryListByWrapper) - reverselyQuery:字段组件数据回填。(
queryListByWrapper) - reverselyQueryWithSize:级联字段组件数据回填。(
queryListByWrapper) - fetchExpandEndLevel:初始加载时展开到指定层级的查询。(
queryListByWrapper)
- fetchAll:一次性加载。(
提示
所有树查询接口都会调用模型对应的数据管理器函数,可以通过重写的方式修改其查询结果。
二、DSL 结构
一个精简版视图可以是这样的:(只有一层节点配置的自关联树)
<view model="business.PamirsDepartment" type="tree" name="demo_tree_view">
<template slot="actionBar">
<action name="redirectCreatePage" label="创建" />
</template>
<template slot="tree">
<nodes>
<node label="activeRecord.name" model="business.PamirsDepartment" selfReferences="parent" />
</nodes>
<template slot="rowActions">
<action name="redirectUpdatePage" label="编辑" />
<action name="delete" label="删除" />
</template>
</template>
</view>树视图从整体上看包含表头动作和行内动作,nodes 节点用于声明树形结构的节点配置集合,node 节点表示每层节点配置。值得一提的是,行内动作此时将被渲染在每个节点的后面进行展示。
(一)设计原理
在学习和理解 DSL 节点配置之前,我们先来看看基于模型元数据的树所具备的特征。
1、树形数据结构
简而言之,树形结构是一组带有层级关系的集合。集合中的每一项被称为节点,节点与节点之间具备父子、兄弟关系。
例如一个以 JSON 结构表示的树形可以是这样的:
[
{
"key": "1",
"value": "1",
"isLeaf": true
},
{
"key": "2",
"value": "2",
"isLeaf": false,
"children": [
{
"key": "2-1",
"value": "2-1",
"isLeaf": true
}
]
}
]在这个 JSON 中,有三个节点,并且以 children 表示其子节点集合,不存在子节点的节点使用 isLeaf 属性标记为叶节点。
2、关系型数据库中的树形数据结构设计
以 MySQL 数据库为例,通常我们需要表示一个树形结构的表,其设计可能是这样的:
| 字段 | 类型 | 描述 |
|---|---|---|
| code | varchar(128) | 编码(唯一键) |
| name | varchar(128) | 名称 |
| parent_code | varchar(128) | 父编码 |
由此,我们就可以得出这样的一类查询 SQL :
-- 查询顶级节点数据
select code, name where parent_code is null;
-- 根据父编码查询所有的子节点
select code, name where parent_code = '1';这样一个最简单的树形数据结构就可以被业务系统正常使用了。
3、元数据模型中的树形数据结构设计
在元数据模型中,有四个字段类型可以表示模型与模型间关系——关系字段。
- 一对一(O2O)
- 多对一(M2O)
- 一对多(O2M)
- 多对多(M2M)
但并不是所有类型都适用于树形结构的,根据上一节数据库设计的内容,我们可以知道只有多对一(M2O)和一对多(O2M)这两类有可能被用于树形结构。
根据上一节的数据库表设计,我们可以这样定义一个模型:(以 demo.DemoModel 为例)
| 字段 | 类型 | 关联模型 | 关联字段 | 关系字段 |
|---|---|---|---|---|
| code | String | - | - | - |
| name | String | - | - | - |
| parentCode | String | - | - | - |
| parnet | M2O | demo.DemoModel | parentCode | code |
| children | O2M | demo.DemoModel | code | parentCode |
这个模型设计为了表示 M2O 和 O2M 类型的对称设计且都可以适用于树形结构,因此在上表中定义了 parent 和 children 两个字段,通常情况下我们只需要使用其中一个即可。推荐使用 parent 定义树形结构的模型,这样较为贴合数据库设计。
不论使用什么字段类型,其关联模型都是本模型,我们可以称这个模型具备自关联关系,称这两个字段为自关联字段。
4、关联关系的方向性
在我们处理树展开的问题时,我们发现要想构成树形结构,其关联字段总是需要向 “多” 的一方展开。因此我们不得不引入一个关联关系的方向性概念以确保我们的实现方案是有理论支撑的。
不同关联类型的方向性:
- 一对一(O2O):不具备单一方向性,不具备 “多” 的概念。
- 多对一(M2O):具备向 “多” 或 向 “一” 的单一方向性。
- 一对多(O2M):具备向 “一” 或 向 “多” 的单一方向性。
- 多对多(M2M):不具备单一方向性。
一个具有常规意义的树形结构总是向 “多” 的一方展开的,否则这个树形结构是不具备有效业务含义的。
结合我们对关联关系的方向性,我们可以明确的知道:
- 一对一(O2O)一定无法构成一个常规意义的树形结构的;
- 多对一(M2O)和一对多(O2M)都具备向 “多” 的一方展开的单一方向性;
- 多对多(M2M)本质上是一对多(O2M)和多对一(M2O)的结合,虽然不具备单一方向性,但其具备 “多” 的概念,因此我们可以暂时将其类比为一对多类型向 “多” 的一方展开。
在这里我们仅引入基本概念,在下面 “查询原理” 小节中会对这一问题进行详细介绍。
5、节点配置
让我们先来看看树组件/级联组件的所有配置项:
| 属性 | 类型 | 描述 |
|---|---|---|
| model | string | 模型编码,用于确定当前节点所对应的模型数据的来源。 |
| label | string|expression | 标题,每个节点的展示内容。activeRecord 表示当前节点的数据 |
| labelFields | string[] | 标题字段 |
| searchFields | string[] | 搜索字段 |
| selfReferences | string | 自关联字段。 当前节点允许使用自关联字段无限展开时,可使用该配置。 |
| references | string | 与上一级节点之间的关联字段。 除第一级节点外,其他节点必须配置。 |
| search | string | 点击搜索字段 在左树右表中,树作为二级搜索时使用该字段对表格进行过滤。 |
string | 级联卡片标题 |
selfReferences、references、search 格式
为了方便配置,这三个属性都允许使用以下格式进行配置:
${model}#${field}
<nodes>
<node model="business.PamirsCompany" />
<node model="business.PamirsDepartment" references="business.PamirsDepartment#companyCode" />
</nodes>等价于
<nodes>
<node model="business.PamirsCompany" />
<node model="business.PamirsDepartment" references="companyCode" />
</nodes>即:当关联字段在当前节点的模型中时,可使用缺省当前模型编码的写法简化配置;模型编码只有可能是当前节点模型和相邻节点模型。
(二)查询原理和配置方式
1、使用多对一关联字段构成树
以 “公司 - 部门 - 员工” 这样标准的组织架构模型为例,当我们需要构建一个具备这三个模型的树形结构时,我们可以这样定义节点:
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="department" />
</nodes>其中:
PamirsCompany模型需要通过partnerType过滤所有的公司数据。PamirsDepartment模型中有一个company多对一字段。- 关联模型(references):
PamirsCompany - 关联字段(relationFields):
companyCode - 关系字段(referenceFields):
code
- 关联模型(references):
PamirsEmployee模型中有一个department多对一字段。- 关联模型(references):
PamirsDepartment - 关联字段(relationFields):
departmentCode - 关系字段(referenceFields):
code
- 关联模型(references):
提示
模型定义、字段配置以及关联关系字段,后端可通过查看源码或通过数据库的 base_field 表进行查询,前端可通过 ModelCache#get 方法在浏览器控制台输出进行查看。
查询流程
- 使用以下 SQL 查询公司:
select id, code, name from business_pamirs_partner where partner_type = 'COMPANY' and is_deleted = 0 order by create_date desc, id desc;其中,partner_type = 'COMPANY' 就是节点上的 filter 过滤表达式,排序为模型默认排序规则。
- 当展开公司节点查询部门列表时,需携带当前公司编码在部门表中进行查询,即可得到当前公司下的所有部门,对应的 SQL 为:(以当前公司编码为
cs为例)
select id, code, name from business_pamirs_department where company_code = 'cs' and is_deleted = 0 order by create_date desc, id desc;- 当展开部门节点查询员工列表时,需携带当前部门编码在员工表中进行查询,即可得到当前部门下的所有员工,对应的 SQL 为:(以当前部门编码为
ds为例)
select id, code, name from business_pamirs_employee where department_code = 'ds' and is_deleted = 0 order by create_date desc, id desc;2、使用一对多关联字段构成树
同样以 “公司 - 部门 - 员工” 这样的组织架构为例,我们还可以通过一对多(O2M)关联字段构建树形结构:(为了方便理解,我们与上一小节的示例作为对照进行介绍)
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="business.PamirsCompany#departmentList" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="business.PamirsDepartment#employees" />
</nodes>我们可以发现,第一级的公司节点定义并无变化,从第二级开始,指定 references 使用了上一级模型的一对多(O2M)字段进行关联。
其中:
PamirsCompany模型需要通过partnerType过滤所有的公司数据。PamirsCompany模型中有一个departmentList一对多字段。- 关联模型(references):
PamirsDepartment - 关联字段(relationFields):
code - 关系字段(referenceFields):
companyCode
- 关联模型(references):
PamirsDepartment模型中有一个employeeList一对多字段。(该字段在代码中实际上是多对多字段,此处仅用于示例介绍)- 关联模型(references):
PamirsEmployee - 关联字段(relationFields):
code - 关系字段(referenceFields):
departmentCode
- 关联模型(references):
其查询过程与多对一关联字段构成树的查询过程完全一致。
由此我们可以发现,树结构的查询原理与其关联字段总是需要向 “多” 的一方展开这两者之间产生了相互约束,因此,不论我们通过多对一还是一对多来配置一个树形结构,其关联字段总是需要向 “多” 的一方展开。
提示
学习了多对一和一对多的查询原理,让我们再来试着理解一下 “关联字段总是需要向 “多” 的一方展开” 这个基本概念。
以 “多对一” 关联字段来描述模型间关系时我们可以这样说:每个部门有唯一的所属公司,每个员工有唯一的所属部门。
以 “一对多” 关联字段来描述模型间关系时我们可以这样说:公司下有多个部门,且每个部门只能在一个公司中;每个部门下有多个员工,且每个员工只能在一个部门中。
这也从一方面体现了多对一和一对多关系具有对称性,不论从什么角度出发,其模型间关系都是向 “多” 的一方展开的,且都具备单一的方向性。
3、使用多对多关联字段构成树
同样以 “公司 - 部门 - 员工” 这样的组织架构为例,我们还可以通过多对多(M2M)关联字段构建树形结构:
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="business.PamirsCompany#departmentList" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="business.PamirsDepartment#employeeList" />
</nodes>我们可以发现,第一级的公司节点定义并无变化,从第二级开始,指定 references 使用了上一级模型的多对多(M2M)字段进行关联。
其中:
PamirsCompany模型需要通过partnerType过滤所有的公司数据。PamirsCompany模型中有一个departmentList多对多字段。(该字段在代码中实际上是多对多字段,此处仅用于示例介绍)- 关联模型(references):
PamirsDepartment - 关联字段(relationFields):
code - 关系字段(referenceFields):
code - 中间模型(through):
CompanyRelDepartment - 中间模型关联字段(throughRelationFields):
companyCode - 中间模型关系字段(throughReferenceFields):
departmentCode
- 关联模型(references):
PamirsDepartment模型中有一个employeeList多对多字段。- 关联模型(references):
PamirsEmployee - 关联字段(relationFields):
code - 关系字段(referenceFields):
code - 中间模型(through):
DepartmentRelEmployee - 中间模型关联字段(throughRelationFields):
departmentCode - 中间模型关系字段(throughReferenceFields):
employeeCode
- 关联模型(references):
查询流程
- 使用以下 SQL 查询公司:
select id, code, name from business_pamirs_partner where partner_type = 'COMPANY' and is_deleted = 0 order by create_date desc, id desc;其中,partner_type = 'COMPANY' 就是节点上的 filter 过滤表达式,排序为模型默认排序规则。
- 当展开公司节点查询部门列表时,首先需携带当前公司编码在公司和部门中间表中查询所有部门的编码,对应的 SQL 为:(以当前公司编码为
cs为例)
select department_code from business_company_rel_department where company_code = 'cs' and is_deleted = 0;- 拿到上一步中查询的所有部门编码,在部门表中根据
code字段查询对应的部门:(假设上一步查询的结果为:ds1, ds2, ds3)
select id, code, name from business_pamirs_department where code in ('ds1', 'ds2', 'ds3') and is_deleted = 0 order by create_date desc, id desc;- 当展开部门节点查询员工列表时,首先需携带当前部门编码在部门和员工中间表中查询所有员工的编码,对应的 SQL 为:(以当前部门编码为
ds1为例)
select employee_code from business_department_rel_employee where department_code = 'ds1' and is_deleted = 0;- 拿到上一步中查询的所有员工编码,在员工表中根据
code字段查询对应的员工:(假设上一步查询的结果为:es1, es2, es3)
select id, code, name from business_pamirs_employee where code in ('es1', 'es2', 'es3') and is_deleted = 0 order by create_date desc, id desc;提示
试想一下,如果多对多字段使用当前模型字段,其查询流程还可以向预想中那样执行吗?
4、使用自关联字段构成树
当 “部门” 模型具备上下级关系时,我们希望树形结构可以表示出部门的上下级关系。显而易见的是,基于我们上面已知的查询原理,我们可以这样定义节点:
<nodes>
<node label="activeRecord.name" model="business.PamirsDepartment" filter="parentCode =isnull= true" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="parent" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="parent" />
</nodes>其中:
- 第一级部门为根部门,通过
parentCode为空这一条件我们可以得到没有上级部门的所有部门。 - 第二级和第三级通过
parent多对一字段进行查询,根据多对一关联字段构成树的查询原理,我们可以知道最终的 SQL 会在部门表中根据将当前部门的编码(code)作为上级部门编码(parentCode)在部门表中继续发起查询得到当前部门的下级部门。
此时,我们已经看到了自关联树形结构的基本雏形,但上面的配置只配置了三级,我们无法继续向下展开。要想做到无限层级的自关联树形结构,我们需要明确区分关联字段和自关联字段的配置。将上述配置转换为自关联树形结构,我们可以这样定义节点:
<nodes>
<node label="activeRecord.name" model="business.PamirsDepartment" selfReferences="parent" />
</nodes>看到这样的节点配置是不是很熟悉?没错,这是我们在设计原理最开始所展示的自关联树形结构配置。
这样的配置会在查询第一级数据时,自动通过 parentCode 为空这一条件进行过滤,无需手动添加过滤条件,第二级之后,每一级都会向下展开,直到没有下级节点为止。
5、综合使用
上面的介绍中,我们分别介绍了不同类型的关联字段以及自关联字段的查询原理,在实际使用时,我们可能会根据实际场景综合使用。
例如 “公司 - 部门 - 员工” 这样标准的组织架构模型中,部门模型会通过自关联向下展开,其他节点仅做展开,在这种情况下,我们是如何进行查询的呢?先来看这样的节点定义:
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" selfReferences="parent" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="business.PamirsDepartment#employeeList" />
</nodes>其中:
PamirsCompany模型需要通过partnerType过滤所有的公司数据。- 部门节点通过
PamirsCompany模型中的company多对一字段进行层级关联,并且通过parent多对一字段进行自关联。 - 员工节点通过
PamirsCompany模型中的employeeList多对多字段进行层级关联。
在查询时,层级与层级之间的查询原理保持不变,但发现部门节点具备自关联字段配置时,将优先使用自关联字段逐级进行查询,直到没有下级部门为止。若当前部门没有下级部门,则查询下一级员工数据作为树形结构的子节点进行返回。
查询流程图解
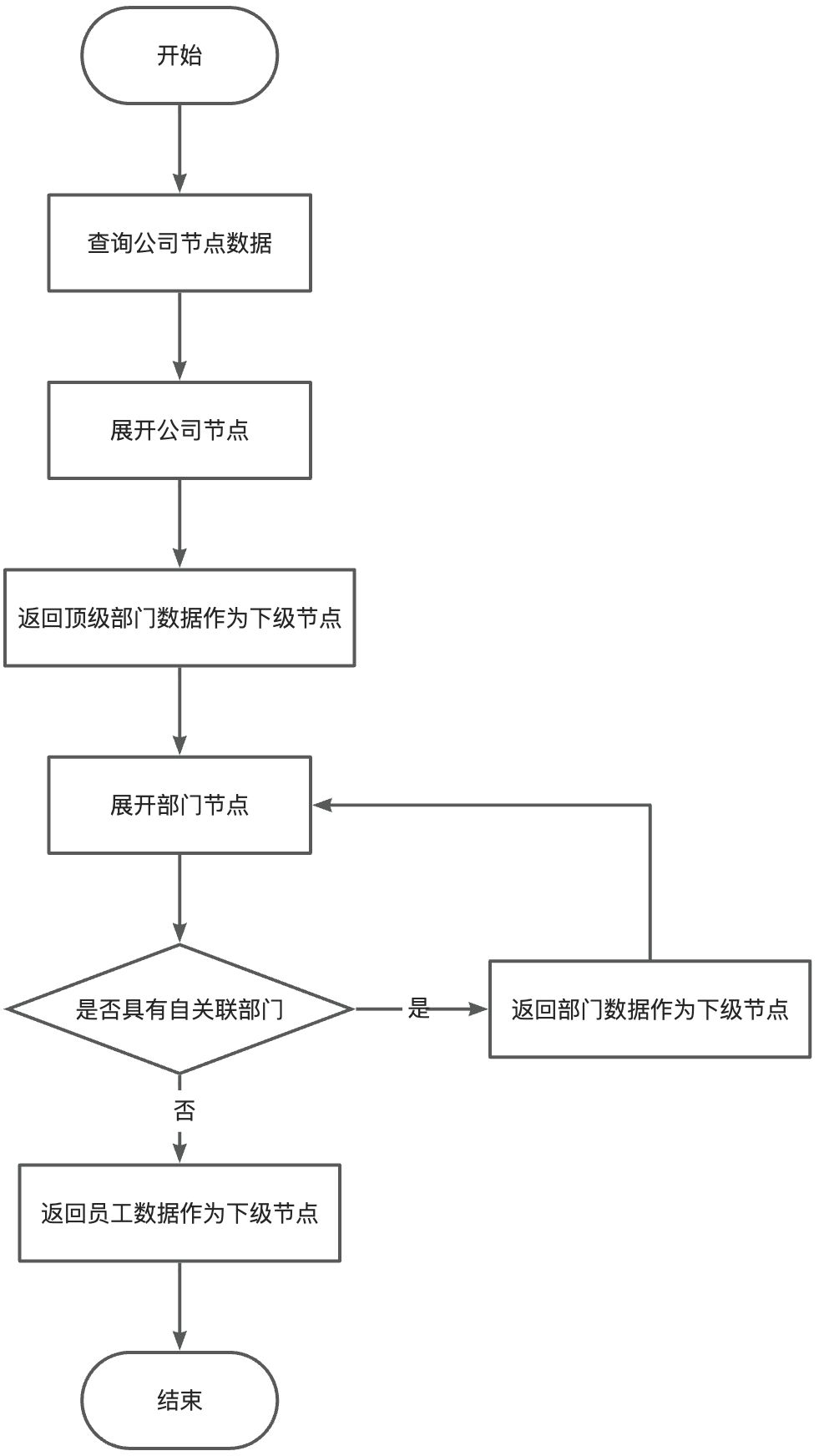
提示
从上述的查询流程来看,员工只有在部门的叶节点被作为下级节点返回,中间层级的部门无法查看其下面的员工数据。带来这个约束的原因主要在于三点:
- 为了保证单个层级的数据具备单一模型的特征,因此没有在一个层级中包含多个模型的数据。
- 在查询性能方面,多个模型的数据总是需要在展开每一级节点时查询其他节点。
- 在同一层树节点下,出现多个模型的数据容易在大多数场景中产生误解,比如公司节点下出现了员工数据。
6、多对多关联字段的方向性
使用上面介绍的节点配置和查询原理,我们已经可以配置出任何模型所构成的树形结构了。为了回答之前我们提出的多对多关联字段的方向性问题,也更近一步向读者解释方向性的问题,我们补充说明一下多对多关联字段的配置方法,以及一个基于假设的特殊判断逻辑。
在开始之前,先来看看这两段节点定义:
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="business.PamirsCompany#departmentList" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="business.PamirsDepartment#employeeList" />
</nodes><nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="business.PamirsCompany#departmentList" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="departmentList" />
</nodes>相比之下,两段节点定义唯一的不同在于第三级节点的员工节点配置,而实际运行时,这两段节点定义将会产生相同的结果。
下面列出了这两个字段的元数据信息:
PamirsDepartment模型中有一个employeeList多对多字段。- 关联模型(references):
PamirsEmployee - 关联字段(relationFields):
code - 关系字段(referenceFields):
code - 中间模型(through):
DepartmentRelEmployee - 中间模型关联字段(throughRelationFields):
departmentCode - 中间模型关系字段(throughReferenceFields):
employeeCode
- 关联模型(references):
PamirsEmployee模型中有一个departmentList多对多字段。- 关联模型(references):
PamirsDepartment - 关联字段(relationFields):
code - 关系字段(referenceFields):
code - 中间模型(through):
DepartmentRelEmployee - 中间模型关联字段(throughRelationFields):
employeeCode - 中间模型关系字段(throughReferenceFields):
departmentCode
- 关联模型(references):
可以看到,这两个字段在两个模型中也是对称定义的,其关联关系都保存在 DepartmentRelEmployee 模型中。
按照之前我们了解的多对多关联字段的方向性概念,其本身并不具备单一方向性。在模型语义的帮助下,我们可以得到这样的解释:
PamirsDepartment#employeeList字段表示一个部门下有多个员工,每个员工可能出现在多个部门PamirsEmployee#departmentList字段表示一个员工下有多个部门,每个部门可能出现在多个员工。(这是一个语义病句,正常情况的表达应该是:一个员工属于多个部门)
以一对多(O2M)的视角来看,部门 - 员工可以是向 “多” 的一方展开,而员工 - 部门也可以是向 “多” 的一方展开,即:当字段定义在哪个模型上,哪个模型就可以是 “一”,关联模型总是 “多” 。
那么,我们是如何识别语义做到总是得到 “部门 - 员工” 这一方向性的呢?
这是一个基于单一方向性假设的答案:
- 当多对多关联字段在当前节点模型上时,其关联模型一定是下级节点模型,其多对多字段表示当前模型向关联模型展开,例如:
PamirsDepartment#employeeList字段。 - 当多对多关联字段在下级节点模型上时,其关联模型一定是当前模型,其多对多字段表示关联模型向当前模型展开。例如:
PamirsEmployee#departmentList字段。
提示
当然,这一假设并不是在任何场景都适用的,当语义场景并不能像 “部门 - 员工” 这样具备单一方向性时,这一假设也就无法成立了,甚至这一假设可能对某些业务场景产生困扰。
三、节点配置示例
在使用界面设计器配置具有树形结构的组件时,总能看到一段 “未构成完整关联关系” 的字样,这一提示应该难倒了不少读者和使用者。
通过下面我们提供的一系列示例,你可以了解:
- 从 DSL 结构和元数据的角度来理解如何正确配置完整关联关系。
- 模型约束在树视图以及树选择组件中的规范。
- 树组件的节点动作如何配置。
(一)树视图中的树组件
在我们学习视图时,每个视图都具有模型,其所有 DSL 元数据都围绕模型展开。树视图也不例外,在树视图中配置树组件时,其最后一级节点模型必须与当前视图模型相同。
1、单个节点的树组件配置
在配置一个部门模型的树视图时,可以是这样的:
<view model="business.PamirsDepartment" type="tree" name="demo_tree_view">
<template slot="actionBar">
<action name="redirectCreatePage" label="创建" />
</template>
<template slot="tree">
<nodes>
<node label="activeRecord.name" model="business.PamirsDepartment" selfReferences="parent" />
</nodes>
<template slot="rowActions">
<action name="redirectUpdatePage" label="编辑" />
<action name="delete" label="删除" />
</template>
</template>
</view>此时,部门模型的数据将通过树形结构使用自关联字段被展开,同时每个节点的后面可以看到 “编辑” 和 “删除” 这两个动作。在这个视图中,不论是节点的模型,还是动作的模型都是当前视图模型对应的元数据,且不存在其他模型的元数据。
2、多个节点的树组件配置
在配置一个员工模型的树视图时,可以是这样的:
<view model="business.PamirsEmployee" type="tree" name="demo_tree_view">
<template slot="actionBar">
<action name="redirectCreatePage" label="创建" />
</template>
<template slot="tree">
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" selfReferences="parent" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="department" />
</nodes>
<template slot="rowActions">
<action name="redirectUpdatePage" label="编辑" />
<action name="delete" label="删除" />
</template>
</template>
</view>在这个视图中,有三级节点配置,最后一级节点模型与当前视图模型相同,其他的并没有什么变化。
细心的读者可能已经发现,rowActions 插槽被定义在树组件的下面,此时这些节点动作将被如何渲染在页面上呢?
我们约定配置在树组件下的 rowActions 插槽仅会被渲染在与当前视图模型相同的对应节点上,其他节点不使用这些动作。这样做将完全符合 “MVVM” 设计思路,对应模型的动作只会处理对应的模型数据,以确保执行的正确性。
3、节点下的动作配置
虽然定义在树组件下的 rowActions 插槽在一定程度上也能满足我们的业务需求,但在 DSL 设计时,我们希望 DSL 的结构和语义可以更符合 “直觉”。因此也支持在节点下定义 rowActions 插槽,就像这样:
<view model="business.PamirsEmployee" type="tree" name="demo_tree_view">
<template slot="actionBar">
<action name="redirectCreatePage" label="创建" />
</template>
<template slot="tree">
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" selfReferences="parent" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="department">
<template slot="rowActions">
<action name="redirectUpdatePage" label="编辑" />
<action name="delete" label="删除" />
</template>
</node>
</nodes>
</template>
</view>此时,rowActions 插槽被定义在最后一级节点的下面,用来表示这些动作仅在员工模型数据被渲染在页面上时进行展示,其他节点不具备任何动作。
4、不同节点下的动作
有没有一种可能在 “公司” 或 “部门” 节点下面也渲染对应模型的动作呢?答案是肯定的。
<view model="business.PamirsEmployee" type="tree" name="demo_tree_view">
<template slot="actionBar">
<action name="redirectCreatePage" label="创建" />
</template>
<template slot="tree">
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY">
<template slot="rowActions">
<action model="business.PamirsCompany" name="redirectUpdatePage" label="编辑" />
<action model="business.PamirsCompany" name="delete" label="删除" />
</template>
</node>
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" selfReferences="parent">
<template slot="rowActions">
<action model="business.PamirsDepartment" name="redirectUpdatePage" label="编辑" />
<action model="business.PamirsDepartment" name="delete" label="删除" />
</template>
</node>
<node label="activeRecord.name" model="business.PamirsEmployee" references="department">
<template slot="rowActions">
<action name="redirectUpdatePage" label="编辑" />
<action name="delete" label="删除" />
</template>
</node>
</nodes>
</template>
</view>从上面的配置我们可以看到,当视图编译无法正确识别元数据模型时,我们可以通过 model 属性手动指定模型编码,以确保视图编译可以正确执行。
提示
在大多数情况下,我们并不建议打破视图编译的模型限制,但树视图的特殊性又让我们不得不通过指定模型来正确处理元数据以满足业务需求。
5、树组件的展开视图
在选中树节点时,我们希望可以通过一个表单/详情视图来展示这一节点的数据,此时可以通过 content 插槽进行视图配置。一个可能的 DSL 可以是:
<view model="business.PamirsEmployee" type="tree" name="demo_tree_view">
<template slot="actionBar">
<action name="redirectCreatePage" label="创建" />
</template>
<template slot="tree">
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY" />
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" selfReferences="parent" />
<node label="activeRecord.name" model="business.PamirsEmployee" references="department" />
</nodes>
<template slot="content">
<view model="business.PamirsEmployee" type="detail">
<template slot="detail" cols="2">
<field data="id" invisible="true" />
<field data="code" label="员工编码" span="1" />
<field data="name" label="员工名称" span="1" />
</template>
</view>
</template>
</template>
</view>(二)树选择字段组件
当我们对关联关系字段配置树选择组件时,其节点配置与树组件几乎完全一样。唯一的区别在于,构建完整关联关系的判定不同。
任何一个关联关系字段,其最终选中的数据都必须是关联模型的数据,否则将无法正确提交。基于这一约束,我们可以推断出,树选择组件的最后一级节点模型必须与当前字段的关联模型相同。
1、部门树选择组件配置
以 PamirsDepartment 模型的 parent 多对一(M2O)字段为例:(一对多(O2M)/多对多(M2M)配置方法完全一致)
<view model="business.PamirsDepartment" type="form" name="demo_form_view">
<template slot="form" cols="2">
<field data="id" invisible="true" />
<field data="code" label="部门编码" span="1" />
<field data="name" label="部门名称" span="1" />
<field data="parent" label="上级部门" widget="TreeSelect" span="1">
<nodes>
<node label="activeRecord.name" model="business.PamirsDepartment" selfReferences="parent" />
</nodes>
</field>
</template>
</view>2、多个节点的部门树选择组件配置
<view model="business.PamirsDepartment" type="form" name="demo_form_view">
<template slot="form" cols="2">
<field data="id" invisible="true"/>
<field data="code" label="部门编码" span="1"/>
<field data="name" label="部门名称" span="1"/>
<field data="parent" label="上级部门" widget="TreeSelect" span="1">
<nodes>
<node label="activeRecord.name" model="business.PamirsCompany" filter="partnerType == COMPANY"/>
<node label="activeRecord.name" model="business.PamirsDepartment" references="company" selfReferences="parent"/>
</nodes>
</field>
</template>
</view>