Objective: By the end of this section, you should be able to use GraphQL to generate API documentation.
Ⅰ、Backend Interface Implementation Logic Analysis
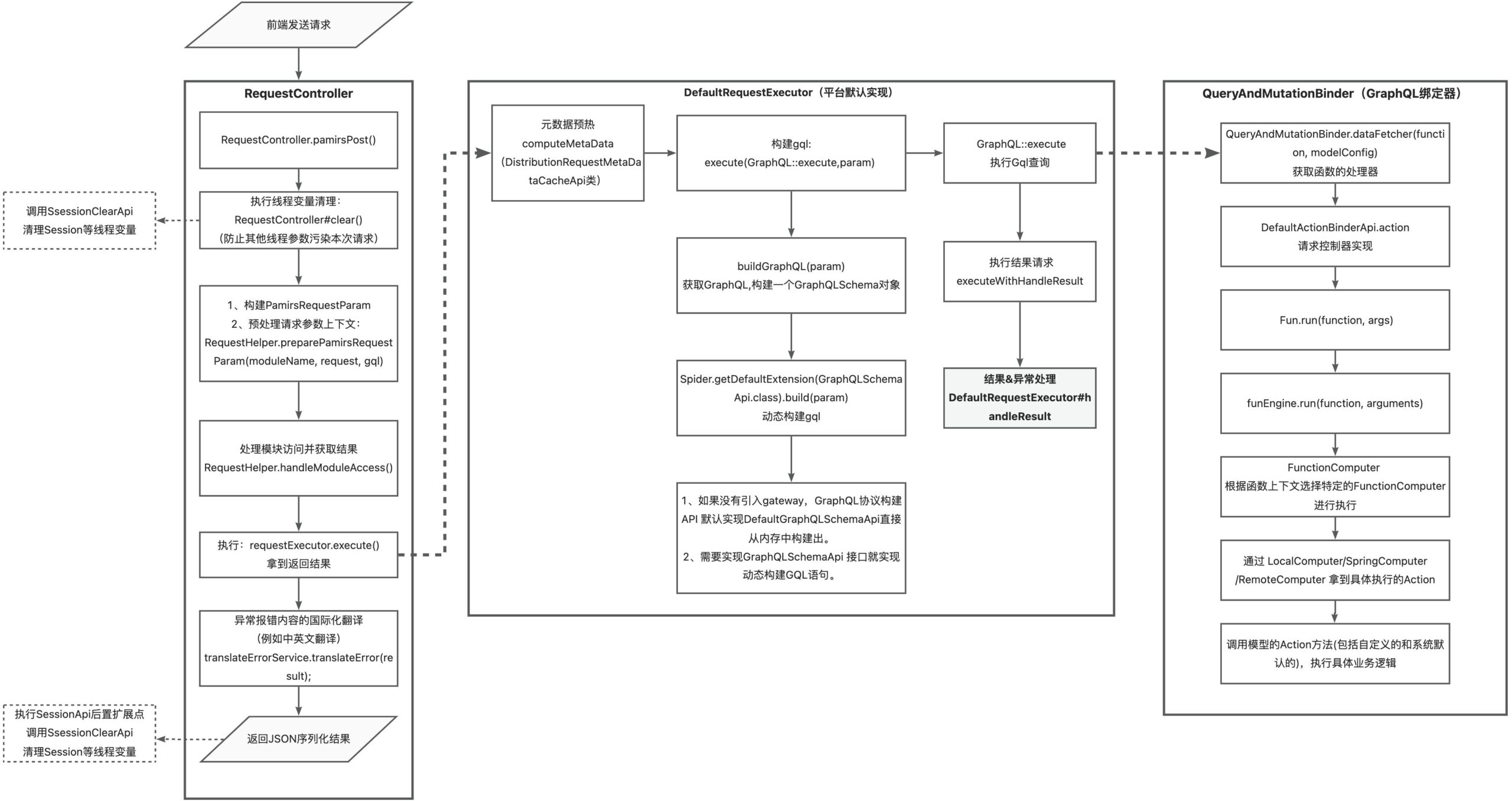
Ⅱ、Generating API Documentation with GraphQL
GraphiQL, a highly popular interactive development environment (IDE) designed for browsing, writing, and testing GraphQL queries, not only assists in querying APIs but also has the capability to generate documentation automatically. The following details the specific steps for using GraphiQL:
Repository address: https://github.com/anvilco/spectaql?tab=readme-ov-file#yaml-options
(Ⅰ)Using GraphiQL Tool to Generate API Documentation
1、Installation and Configuration of GraphiQL
Methods: Install GraphiQL locally or globally.
If your GraphQL API server does not have built-in GraphiQL, you can use a standalone GraphiQL framework or package.
- Global Installation of GraphiQL
If you want to use GraphiQL in a local environment, you can install it vianpmoryarn:
(Use Taobao mirror source if download fails)
npm install -g graphiql- Installation as a Development Dependency via npm or Yarn
You can also installGraphiQLas a development dependency in your project:
npm install graphiql- Generate Your Documentation!
npx spectaql config.ymlRunning this command requires a config.yml file. For specific usage, refer to https://github.com/anvilco/spectaql?tab=readme-ov-file#yaml-options
2、Generating Documentation in JSON Format
Generate or export the schema file.
- Automatic Schema Generation
If you use Java classes and annotations to define your GraphQL API (using@GraphQLQueryand other annotations), the GraphQL schema is typically generated at runtime. You can export the schema manually by accessing the GraphQL endpoint after starting Spring Boot.
The following is an example of an introspection query to help you obtain the schema: This query can be dynamically adjusted based on documentation needs. Query http://127.0.0.1:8091/pamirs/base, ensuring that pamirs.framework.gateway.show-doc: true is enabled in the project yml configuration file.
Note:
pamirs/base is the interface under the base module and can be replaced with a business module to return its interfaces.
query IntrospectionQuery {
__schema {
queryType { ...FullType }
mutationType { ...FullType }
subscriptionType { name }
types {
...FullType
}
directives {
name
description
locations
args {
...InputValue
}
}
}
}
fragment FullType on __Type {
kind
name
description
fields(includeDeprecated: true) {
name
description
args {
...InputValue
}
type {
...TypeRef
}
isDeprecated
deprecationReason
}
inputFields {
...InputValue
}
interfaces {
...TypeRef
}
enumValues(includeDeprecated: true) {
name
description
isDeprecated
deprecationReason
}
possibleTypes {
...TypeRef
}
}
fragment InputValue on __InputValue {
name
description
type { ...TypeRef }
defaultValue
}
fragment TypeRef on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
}
}
}
}
}
}You can place this query in GraphiQL (development tool) or tools like Postman and send the request to /base to obtain the complete schema.
- Access GraphQL Endpoint: When the application is running, the GraphQL API is typically exposed at the
/basepath. You can export the full GraphQL schema via anintrospectionquery.
Save the request response as a JSON file and configure it in config.yml. Configuration reference: https://github.com/anvilco/spectaql/blob/main/config-example.yml
spectaql:
# Optional path to the target build directory.
# Set to null to not write the output to the filesystem, making it only available via the API (default: public)
#
# Default: public
targetDir: /Users/mmy/Desktop
themeDir: /Users/mmy/Desktop
introspection:
# File containing a GraphQL Schema Definition written in SDL.
# Can also pass an array of paths (or glob supported by @graphql-tools/load-files)
# like so:
# schemaFile:
# - path/to/schema/part1.gql
# - path/to/schema/part2.gql
# schemaFile: /Users/mmy/Desktop/schema2.graphql
# File containing Introspection Query response in JS module export, or JSON format
introspectionFile: /Users/mmy/Documents/response2.json
#
# URL of the GraphQL endpoint to hit if you want to generate the documentation based on live Introspection Query results
# NOTE: If not using introspection.url OR servers[], you need to provide x-url below
# url: 'http://127.0.0.1:8091/pamirs/graphql'
extensions:
# Utilize the 'graphql-scalars' library when generating examples for scalars it supports that
# do not have an example already set via some other method. Usually this is a good
# thing to have on, but it is possible to turn it off.
# Default: true
graphqlScalarExamples: true
servers:
- url: http://127.0.0.1:8091/pamirs/baseRun the command npx spectaql config.yml to get an HTML API document!
Note:
The execution time of this command to generate documentation is closely related to the file size. The platform interface execution takes approximately 1-2 hours—please be patient if there are no errors!
(Ⅱ)Generating Documentation by Parsing the schema.json File
If the first method fails, use the following solution: Manually parse the JSON file generated by the GQL request in the first step to generate documentation. Here is a Java code example for parsing the JSON file, which you can modify according to actual needs for the generated format.
Sample code: gql-schema-api
Rule Description:
- Data Extraction Scope: Mainly extract content under "types" in "__schema".
- Interface Area Data Determination and Extraction: When the "kind" of a type is "OBJECT" and the "args" under its "fields" have values, this part belongs to interface area data. The interface name is formed by connecting "name" and "fields" "name" with "/". The interface description intercepts "description" from "fields". From "type" under "args", if "kind" is "INPUT_OBJECT", extract its "name" as the request parameter name; from "type" of "fields", if "kind" is "OBJECT", extract its "name" as the return parameter name.
- Interface Area Data Record Format: Display interface address, interface method, request parameter name, and return parameter name in a table.
- Request Parameter Area Data Determination and Extraction: When "kind" is "INPUT_OBJECT", this part is the request parameter area. Extract "name" as the request parameter name, and for "inputFields", use "name" as the field name and intercept "description" as the display name. If the "kind" under "type" of "inputFields" is "SCALAR", extract "name" as the field type.
- Request Parameter Area Data Record Format: Display request parameter names and corresponding (field name, field type, display name, remarks) in a table, with remarks empty.
- Return Parameter Area Data Determination and Extraction: When "kind" is "OBJECT" and "args" under "fields" have no values, this part is the return parameter area. Extract "fields", use "name" as the field name, and intercept "description" as the display name. If the "kind" under "type" of "fields" is "SCALAR", extract "name" as the field type.
- Return Parameter Area Data Record Format: Display return parameter names and corresponding (field name, field type, display name, remarks) in a table, with remarks empty.
- Interface Name Exclusions: Interface names should not include "construct", "queryByPk", "queryListByEntity", "queryOneByWrapper".
- Overall Processing Flow: Process the interface list, request parameter data area, and return parameter data area separately as described above.
- Request Parameter Association Display: In the processed interface list, query corresponding parameter information in the request parameter data area based on the request parameter name, and display (field name, field type, display name, remarks) in a table after the corresponding interface information.
- Return Parameter Association Display: In the processed interface list, query corresponding parameter information in the return parameter data area based on the return parameter name, and display (field name, field type, display name, remarks) in a table below the request parameters of the corresponding interface.