I. Mandatory Constraints for Distributed Invocation
- Mandatory Requirement - Library Usage in Distributed Invocation: In distributed invocation scenarios, the base library and Redis must be used together to ensure consistency and efficiency in system data interaction and storage.
- Mandatory Requirement - Library Consistency in Designer Environment: If a designer exists in the environment, the base library and Redis used by the designer must not only be consistent with each other but also match the base library and Redis used in other parts of the project to ensure uniformity of the entire system data environment.
- Mandatory Requirement - Data Source Consistency Under the Same Base Library: In the same base library environment, data sources of the same module in different applications must be consistent, which is crucial for maintaining data accuracy and stability and ensuring smooth data interaction between different applications.
- Mandatory Requirement - Introduction of Distributed Cache Package in Projects: Distributed cache packages must be introduced in the project. Specifically, refer to the distributed package dependencies mentioned below to meet the system's cache management needs under the distributed architecture.
II. Distributed Support
(Ⅰ) Distributed Package Dependencies
- Add dependencies of pamirs-distribution in the dependency management of the parent pom:
<dependency>
<groupId>pro.shushi.pamirs</groupId>
<artifactId>pamirs-distribution</artifactId>
<version>${pamirs.distribution.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>- Add pamirs-distribution related packages in the boot project:
<!-- Distributed service publication -->
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-faas</artifactId>
</dependency>
<!-- Distributed metadata cache -->
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-session</artifactId>
</dependency>
<dependency>
<groupId>pro.shushi.pamirs.distribution</groupId>
<artifactId>pamirs-distribution-gateway</artifactId>
</dependency>- Add the class annotation @EnableDubbo in the Application of the startup project:
@EnableDubbo
public class XXXStdApplication {
public static void main(String[] args) throws IOException {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// ………………………………
log.info("XXXX Application loading...");
}
}(Ⅱ) Modify the bootstrap.yml File
Note the serialization method: serialization: pamirs
The following is just an example (with zk as the registry), and the registry supports both zk and Nacos:
spring:
profiles:
active: dev
application:
name: pamirs-demo
cloud:
service-registry:
auto-registration:
enabled: false
pamirs:
default:
environment-check: true
tenant-check: true
---
spring:
profiles: dev
cloud:
service-registry:
auto-registration:
enabled: false
config:
enabled: false
uri: http://127.0.0.1:7001
label: master
profile: dev
nacos:
server-addr: http://127.0.0.1:8848
discovery:
enabled: false
namespace:
prefix: application
file-extension: yml
config:
enabled: false
namespace:
prefix: application
file-extension: yml
dubbo:
application:
name: pamirs-demo
version: 1.0.0
registry:
address: zookeeper://127.0.0.1:2181
protocol:
name: dubbo
port: -1
serialization: pamirs
scan:
base-packages: pro.shushi
cloud:
subscribed-services:
metadata-report:
disabled: trueNote: For more YAML configurations, please refer to Module API.
(Ⅲ) Minimum Set for Module Startup
pamirs:
boot:
init: true
sync: true
modules:
- base
- Business project's ModuleNote: For more YAML configurations, please refer to Module API.
(Ⅳ) Dependency Relationships Between Business Models
- Service Caller (Client) in Startup YML Configuration: The service caller (Client) should not install the service provider's Module in the
modulesconfiguration of the startup yml file. This operation ensures the simplicity and pertinence of the Client's startup configuration, avoiding the introduction of unnecessary modules and improving startup efficiency and system stability. - Service Caller (Client) in Project pom Configuration: The project pom file of the service caller (Client) should only depend on the service provider's API, that is, only depend on the models and API interfaces defined by the service provider. In this way, the Client can clearly define the dependency scope, focus on the core interface part required for interaction with the service provider, reduce potential risks caused by unnecessary dependencies, and enhance the project's maintainability and scalability.
- Service Caller (Client) in Project Module Definition: When the service caller (Client) defines the project module (i.e., model Module definition), the service provider's Module should be added to the
dependenciesconfiguration. For example, theFileModulein the sample code below. This operation enables the Client to reasonably integrate the relevant function modules of the service provider within its own module system, ensuring the integrity and consistency of project functions to achieve effective docking and collaborative work with the service provider.
@Module(
name = DemoModule.MODULE_NAME,
displayName = "oinoneDemo工程",
version = "1.0.0",
dependencies = {ModuleConstants.MODULE_BASE, CommonModule.MODULE_MODULE,
FileModule.MODULE_MODULE, SecondModule.MODULE_MODULE/**服务提供方的模块定义*/
}
)- Service Caller (Client) in Startup Class: The
ComponentScanof the startup class needs to configure the package where the service provider's API definition is located. For example,pro.shushi.pamirs.secondin the sample code below:
@ComponentScan(
basePackages = {"pro.shushi.pamirs.meta",
"pro.shushi.pamirs.framework",
"pro.shushi.pamirs",
"pro.shushi.pamirs.demo",
"pro.shushi.pamirs.second" /**服务提供方API定义所在的包*/
},
excludeFilters = {
@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
value = {RedisAutoConfiguration.class, RedisRepositoriesAutoConfiguration.class,
RedisClusterConfig.class}
)
})
@Slf4j
@EnableTransactionManagement
@EnableAsync
@EnableDubbo
@MapperScan(value = "pro.shushi.pamirs", annotationClass = Mapper.class)
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class, FreeMarkerAutoConfiguration.class})
public class DemoApplication {(Ⅴ) Module Startup Sequence
The service provider's modules need to start first. Reason: During the startup process, modules will verify whether dependent modules exist.
(Ⅵ) Dubbo Logging Related
Turn off Dubbo metadata reporting:
dubbo:
metadata-report:
disabled: trueIf error logs still appear after turning off metadata reporting, configure in log:
logging:
level:
root: info
pro.shushi.pamirs.framework.connectors.data.mapper.PamirsMapper: info
pro.shushi.pamirs.framework.connectors.data.mapper.GenericMapper: info # mybatis sql日志
RocketmqClient: error
# Dubbo相关的日志
org.apache.dubbo.registry.zookeeper.ZookeeperRegistry: error
org.apache.dubbo.registry.integration.RegistryDirectory: error
org.apache.dubbo.registry.client.metadata.store.RemoteMetadataServiceImpl: off
org.apache.dubbo.metadata.store.zookeeper.ZookeeperMetadataReport: off
org.apache.dubbo.metadata.store.nacos.NacosMetadataReport: offNote: For more YAML configurations, please refer to Module API.
III. Distributed Support - Transaction Related
(Ⅰ) Distributed Transaction Solutions
Completing a certain business function may require spanning multiple services and operating multiple databases, which involves distributed transactions. Distributed transactions aim to ensure data consistency across different resource servers. Typical distributed transaction scenarios include:
- Cross-database transactions, supplement specific scenarios;
- Cross-internal services brought by microservice splitting;
- Cross-external services brought by microservice splitting;
(Ⅱ) Transaction Strategies
Adopting a microservice architecture requires considering distributed transaction issues (i.e., data consistency between platform subsystems):
- For individual systems/modules, such as the inventory center and account center, use strong transaction methods. For example, when deducting inventory, changes in inventory logs and inventory quantities are included in one transaction to ensure that data in both tables is successfully updated or failed simultaneously. Strong transaction management uses a coding approach, and Oinone transaction management is compatible with Spring's transaction management methods.
- To improve system availability, scalability, and performance, in addition to using strong consistency for certain key businesses and scenarios with particularly high data consistency requirements, it is recommended to adopt a final consistency solution for other scenarios; for distributed transactions, adopt final data consistency, which is achieved through reliable messages, Jobs, and other means.
1. Transaction Messages Based on MQ
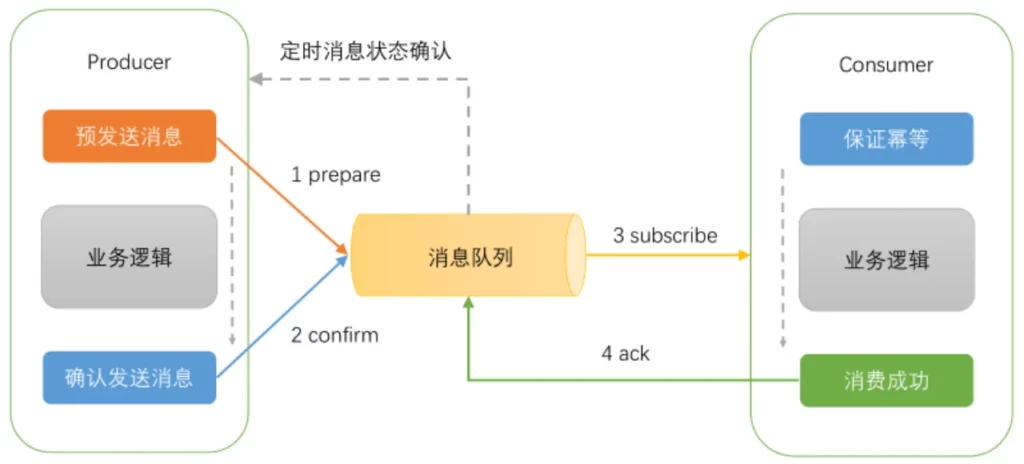
Adopt a final consistency solution based on MQ transaction messages. The logic of transaction messages is guaranteed by the sender (Producer) (the consumer does not need to consider it). The implementation steps based on MQ transaction messages are as follows:
- First, send a transaction message, and MQ marks the message status as Prepared. Note that consumers cannot consume this message at this time.
- Then, execute the business code logic, which may be a local database transaction operation.
- Confirm the sent message. At this time, MQ marks the message status as consumable, and consumers can truly ensure the consumption of this data.
2. Compensation Based on JOB
Regular verification: The passive party of the business activity queries the active party of the business activity according to the timing strategy (the active party provides a query interface) to restore lost business messages.
3. Data Consistency
- Check the design of RPC timeout and retry mechanisms for potential duplicate data issues.
- Consider the design of data idempotency and deduplication mechanisms.
- Consider the design of transaction and data (eventual) consistency.
- When caching data, ensure corresponding mechanisms are in place to maintain the consistency and validity of cached data when underlying data changes.